
- Приговоры важнее ключевых слов
- Принципы ЛОД
- Что такое связанные открытые данные (LOD)?
- Что такое облако связанных открытых данных (LOD)?
- В чем разница между связанными данными и связанными открытыми данными?
- Как LOD приносит пользу издателю (провайдеру электронной коммерции)?
- А как насчет Schema.org Типы?
- Как хэштеги и связанные данные связаны с SEO?
- Предметы действия и забрать
- Связанные преимущества открытых данных
- Семантические SEO ресурсы
Как уже упоминалось в моей колонке оптимизация строкового объекта Использование структурированных данных позволяет поисковым системам, таким как Google, понимать содержание вашей страницы, чтобы оно могло отображать лучшие результаты поиска или ответы на запросы пользователей.
В этом месяце я сосредоточусь на Связанные открытые данные (LOD), что позволит вам публиковать структурированные данные, чтобы их можно было связывать для установления отношений . Это важно, так как отношения между словами позволяют четкое понимание содержания сайта поисковыми роботами.
В моей колонке о понимание сущности поиска Я объяснил, как семантический поиск использует онтологию (или язык), такую как микроданные, RDFa и т. Д., Чтобы разбить предложение на его предмет, предикат и объект, чтобы показать связь между словами в вашем контенте.
Связанные открытые данные основаны на стандартных веб-технологиях, таких как HTTP, RDF, URL-адреса и т. Д., Расширяя их, чтобы они могли автоматически считываться компьютерами. Вот почему для SEO важно понимать и использовать LOD при применении структурированных данных к контенту, чтобы машины могли легче читать этот контент.
Приговоры важнее ключевых слов
LOD используется, чтобы использовать «предложения» в цифровой сфере, как мы делаем это в повседневной жизни. Оптимизация для семантического поиска с использованием LOD заключается в использовании цифрового представления структуры предложений на естественном языке в качестве основы для описания вещей (контента). SEO-разработчики должны обращать внимание на использование предложений, а не ключевых слов, для улучшения контента, публикуемого в Интернете или в интрасетях.
Похоже, что «будущее SEO» потребует более технической подготовки. Большинству SEO, включая меня, придется сотрудничать с семантическим веб-сообществом, чтобы сгладить детали. Это не какая-то новая тактика оптимизации для оптимизации и вставки на свои клиентские страницы. но это та самая ткань Интернета, которая потребует вашего времени, энергии, учебы и настойчивости для ее проработки.
Чтобы объяснить, из чего состоят связанные данные, в простых терминах Тим Бернерс-Ли определил следующие принципы LOD.
Принципы ЛОД
В его Проблемы дизайна: связанные данные Бернерс-Ли предлагает четыре принципа связанных данных (перефразировано ниже):
- Используйте URI (унифицированные идентификаторы ресурсов) для обозначения вещей
- Используйте HTTP URI, чтобы люди или программное обеспечение могли ссылаться на них и находить их от имени людей.
- При поиске URI (вещи), предоставьте полезную информацию, используя стандарты, такие как RDF (Resource Description Framework) или SPARQL (язык запросов RDF)
- Включайте ссылки на другие связанные объекты (URI) при публикации данных в Интернете, чтобы они могли обнаружить другие вещи
Чтобы объяснить больше о том, что такое LOD и как вы можете его использовать, я хотел бы поделиться недавним интервью с Кингсли Иден , основатель и генеральный директор OpenLink Software. Kingsley - признанный в отрасли технологический новатор и поставщик технологий, использующий LOD на предприятии и во всемирной паутине.
Что такое связанные открытые данные (LOD)?
Пол: Кингсли, можешь ли ты дать нам представление о том, что такое ЛОД?
Kingsley: Linked Open Data - это структурированное представление данных, улучшенное за счет использования HTTP URI (ссылок). По сути, речь идет об отношении сущностей - представлении структурированных данных на основе модели, где сущности, атрибуты и значения атрибутов обозначаются («ссылаются») ссылками.
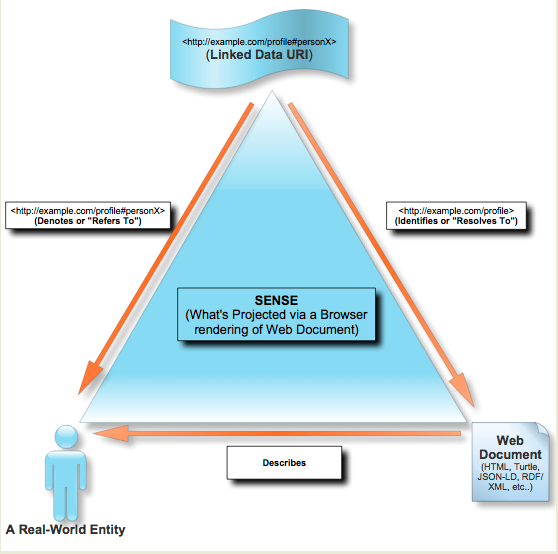
Показано обозначение HTTP URI на основе хеша
HTTP URI неявно открыты в том смысле, что трансляция того, что они обозначают, является функцией протокола HTTP, а не проприетарных протоколов, относящихся к конкретному приложению или платформе.
Можете ли вы привести пример?
Следующее утверждение:
Париж - столица Франции.
Выражает отношение, представленное с использованием нотации на естественном языке, в которой все участники обозначаются буквально словами:
«Париж» «Столица» «Франция»
И каждый из них играет определенную роль, т. Е. «Париж» - это Субъект, «столица», Предикат и «Франция», Объект.
С помощью связанных данных вышеприведенное утверждение может быть дополнено использованием ссылочных (в отличие от литеральных) идентификаторов для обозначения сущностей в ролях: субъект, предикат и объект.
<#Paris> <#capital> <#France>
Если я скопирую приведенные выше утверждения в документ, а затем сделаю документ доступным для пользователей в сети HTTP, я получу документ, который будет автоматически демонстрировать связанные данные из-за того, что у меня будет коллекция ссылок, представленная в моем браузер, который позволяет мне исследовать отношения сущностей, представленные оператором с расширенными ссылками. Семантически, мой единственный документ заявления подразумевает:
<> <#type> <#Document>.
<> <#mentions> <#Paris>.
<> <#mentions> <#Capital>.
<> <#mentions> <#France>.
<#Paris> <#capital> <#France>.
Примечание: «<>» - это просто сокращение, означающее, что HTTP-URL документа должен использоваться в качестве HTTP-URI, обозначающего тему в приведенном выше утверждении. По сути, у вас есть описание документа, который включает в себя описания других вещей. Не отличается от этого интервью, так сказать.
Использование фраз HTTP URI и HTTP URL может сбивать с толку, поэтому лучше посмотреть, как они применяются для обозначения сущностей следующим образом:
- HTTP URI обозначают («ссылаются» или называют) что-либо
- HTTP URL (разновидность HTTP URI) обозначает веб-документы
- WebID (разновидность HTTP URI) обозначает агентов (людей, организации, программное обеспечение, машины и все остальное, способное к механизированной работе)
Что такое облако связанных открытых данных (LOD)?
Я слышал, что LOD Cloud - это огромный массив больших данных, состоящий из наборов данных из различных областей, таких как: общие знания (Википедия), науки о жизни (Bio2RDF), СМИ (BBC), правительство (Data.Gov и Data). Gov.UK) и многие другие. Можете ли вы объяснить LOD Cloud немного подробнее для нас?
Эта огромная коллекция данных представляет собой анклав в Интернете, где все структурированные данные в опубликованных наборах данных представлены и затем опубликованы в соответствии с принципами связанных данных, т. Е. HTTP URI используются для обозначения объектов, потому что это делает структурированные данные webby (или подобный сети). Короче говоря, данные становятся такими же доступными для навигации и обнаружения, как и все остальное в сети HTTP (например, World Wide Web).
Используя мой предыдущий пример, я могу использовать огромное облако LOD в качестве мощного источника идентификаторов, которые обозначают широкий спектр вещей. Например, в моих базовых примерах я могу перекрестно ссылаться на идентификаторы сущностей с помощью идентификаторов из облака LOD следующим образом:
<> <#type> <#Document>.
<> <#mentions> <#Paris>.
<> <#mentions> <#Capital>.
<> <#mentions> <#France>.
<#Paris> <#capital> <#France>.
<#Paris> <#sameAs> <Http://dbpedia.org/resource/Paris> ,
<#France> <#sameAs> <Http://dbpedia.org/resource/France> ,
Пример размещения приведенных выше утверждений в документе, опубликованном в сети HTTP, расширяет базовую демонстрацию того, что Связанные открытые данные согласовывает. Как вы можете видеть, мой обход ссылок больше не ограничен моим документом; Я сделал ссылку на данные в DBpedia, которые в качестве основной распределительной коробки в облаке LOD могли отправлять меня (или агентов) куда угодно.
В чем разница между связанными данными и связанными открытыми данными?
Связанные данные и связанные открытые данные - это одно и то же?
На самом деле, нет. Связь происходит от структуры оператора, основанного на модели объекта (своего рода предложение). Открытость проистекает из использования стандарта для обозначения сущностей в форме HTTP URI. Обратите внимание, что можно создавать коллекции операторов модели отношений сущностей, которые обеспечивают структурированное представление данных с использованием многих видов идентификаторов; магия HTTP URI в качестве механизмов обозначения заключается в лежащей в основе открытости URI и протоколе HTTP.
Вы можете иметь связанные данные, которые не являются «открытыми», используя проприетарные идентификаторы для обозначения сущностей. Короче говоря, так мы все годами работали с компьютерными программами, до появления URI и протокола HTTP. Даже RDF (который требует использования URI и часто ассоциируется со связанными данными), может использоваться для создания связанных данных, которые на самом деле не являются «связанными открытыми данными».
Диаграмма, представленная ниже, имеет большое значение для рассеивания некоторой путаницы, связанной с связанными данными и RDF; напоминая всем о том факте, что «Связанные данные» лежали в основе оригинального дизайна Интернета. Недавно я подправил оригинальное предложение Тима Бернерса-Ли; используя HTTP URI в отличие от строк для обозначения узлов (субъектов или объектов) и коннекторов (предикатов) в сетевой диаграмме (или графике), которая изображает его первоначальное предложение по всемирной паутине.
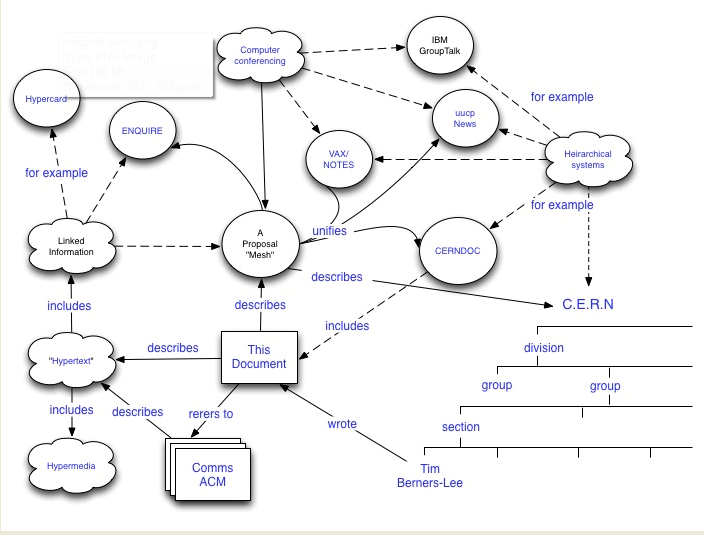
Как LOD приносит пользу издателю (провайдеру электронной коммерции)?
Имея в виду поисковые системы и используя электронную коммерцию в качестве примера, можете ли вы объяснить нам преимущества?
Это увеличивает коэффициент случайного открытия контента (SDQ). Под этим я подразумеваю: это увеличивает степень, в которой контент обнаруживается способом, который «приятно удивляет» пользователей с точки зрения релевантности.
Что такое коэффициент случайного открытия (SDQ)?
SDQ - это показатель для понимания эффектов улучшения представления структурированных данных через HTTP URI. Некоторое время назад Голлихер написал хорошую статью (в ответ на свое первое знакомство с аббревиатурой) под названием: Коэффициент случайного открытия (SDQ): будущее SEO? Или абстрактное понятие?
IQ - это показатель, связанный с человеческим интеллектом. SDQ - это показатель, связанный с веб-интеллектом.
Какую пользу может принести электронная коммерция?
Поставщики электронной коммерции могут на самом деле сосредоточиться на том, что для них действительно естественно, то есть на создании детальных описаний своих продуктов и услуг, зная, что ясность описания в конечном итоге всегда является критическим фактором для обнаружения, которое ведет к росту и удержанию клиентов.
Это в основном подразумевает, что описание сущностей, таких как предложения, продукты, цены, доступность, часы работы и закрытия, и т.д., становится фокусом стратегии веб-контента, гораздо больше, чем эстетика сайта и устаревшие SEO-хаки на основе ключевых слов.
А как насчет Schema.org Типы?
Связаны ли семантическая разметка Schema.org, сущности и LOD друг с другом?
Даже очень! В schema.org у вас есть мощный мост для публикации структурированных данных, который упрощает интеграцию с облаком LOD. Со стороны облака LOD у вас уже есть перекрестные ссылки на schema.org в наборах данных, таких как DBpedia и много других. Все произошло очень естественным образом, а не с помощью грубой силы.
Сегодня многие интернет-магазины уже публикуют структурированные данные, основанные на терминах Schema.org, и тем самым расширяют возможности обнаружения в трех критических областях:
- Поисковые системы
- Социальные медиа
- LOD Cloud
Как хэштеги и связанные данные связаны с SEO?
Барбара Старр рассказывает об отношениях между хэштегами, связанными данными и SEO; не могли бы вы подробнее рассказать об этом?
Хештеги решают проблему, которая долго оспаривает HTTP URI, то есть громоздкую эстетическую природу длинных URI. Благодаря использованию хэштегов, сообщество пользователей Интернета использовало шаблоны, ориентированные на фолксономию, для создания сокращенного шаблона для HTTP URI.
Таким образом, благодаря принятию * hashtag * через поставщиков социальных сетей, вы можете выполнить действие, основанное на HTTP-URI, с помощью практики хэширования. Просто так! Каждый аннотирует сеть таким образом, чтобы добавить больше семантики в связи между сущностями, обозначаемыми этими тегами.
Предметы действия и забрать
Какие действия вы рекомендуете, чтобы SEO были частью LOD?
Поймите, что LOD - это не какая-то страшная загадочная вещь, это специализация для избранных. Вместо этого посмотрите, как пометки (с помощью хэштегов) изменяют способ публикации или отслеживания контента в социальных сетях. Просто нажмите на хэштег в G + или Twitter, например, и вы сразу поймете, что каждый хэштег является действительно супер-ключом, который преобразуется в «тематическую сеть», состоящую из контекстных ссылок на связанные посты, изображения, музыку и видео и т. Д.
Все, что вам нужно сделать, это описать вещи с помощью простых операторов субъекта> предиката> объекта или просто пометить сообщения с помощью хэштегов.
Спасибо, что поделились с нами своими мыслями, Кингсли. Как всегда, изменения на горизонте, и понимание семантической разметки и связанных открытых данных становится все более и более лучшей практикой для оптимизаторов.
Связанные преимущества открытых данных
Ниже приведены некоторые основные причины, по которым специалисты, занимающиеся SEO, должны принять к сведению приведенную выше информацию о связанных открытых данных:
- Открытость : это означает уход от оптимизации для каждой поисковой системы и их периодические изменения алгоритмов ранжирования; это оптимизация для Интернета в целом.
- Экономическая эффективность : долговечность SEO основана на описании сущностей, ориентированных на документы, которые по своей природе не зависят от поисковых систем.
- Обнаруживаемость : это увеличивает случайное обнаружение, сосредотачиваясь на детализации описания объекта.
Для более подробной информации о LOD Cloud я могу сотрудничать с Кингсли в следующей статье. В то же время, смотрите ресурсы LOD ниже для получения дополнительной информации.
Семантические SEO ресурсы
Мнения, выраженные в этой статье, принадлежат автору гостя и не обязательно относятся к Search Engine Land. Штатные авторы перечислены Вот ,
Об авторе
Что такое облако связанных открытых данных (LOD)?В чем разница между связанными данными и связанными открытыми данными?
Как LOD приносит пользу издателю (провайдеру электронной коммерции)?
Org Типы?
Как хэштеги и связанные данные связаны с SEO?
Что такое связанные открытые данные (LOD)?
Пол: Кингсли, можешь ли ты дать нам представление о том, что такое ЛОД?
Можете ли вы привести пример?
Можете ли вы объяснить LOD Cloud немного подробнее для нас?
В чем разница между связанными данными и связанными открытыми данными?