
- Robots.txt
- Robots.txt не хранит файлы из индекса поиска!
- Является ли Robots.txt угрозой безопасности или конфиденциальности?
- Используйте тег <META> роботов, чтобы файлы не попадали в поисковый индекс
- Там нет остановки плохого поведения
Понимание разницы между файлом robots.txt и тегом <META> Robots имеет решающее значение для оптимизации и безопасности поисковой системы. Это может оказать глубокое влияние на конфиденциальность вашего сайта и клиентов. Первое, что нужно знать, это что такое файлы robots.txt и тэги Robots <META>.
Robots.txt
Robots.txt - это файл, который вы помещаете в каталог верхнего уровня вашего сайта, в ту же папку, в которую помещается статическая домашняя страница. Внутри robots.txt вы можете указать поисковым системам не сканировать контент, запретив имена файлов или каталогов. Директива robots.txt состоит из двух частей: пользовательского агента и одной или нескольких запрещающих инструкций.
Пользовательский агент указывает один или все веб-сканеры или пауки. Когда мы думаем о веб-сканерах, мы склонны думать о Google и Bing; однако паук может появиться откуда угодно, а не только из поисковых систем, и многие из них ползут по Интернету.
Вот простой файл robots.txt, сообщающий всем сканерам веб-сайтов о том, что можно спайдерить каждую страницу:
Пользователь-агент: * Disallow:
Чтобы запретить всем поисковым системам сканировать весь сайт, используйте:
Пользователь-агент: * Disallow: /
Разница заключается в косой черте после Disallow:, обозначающей корневую папку и все в ней, включая подпапки и файлы.
Robots.txt является универсальным. Вы можете запретить целые подпапки или отдельные файлы. Вы можете запретить использование определенных поисковых машин, таких как Googlebot и Bingbot. Поисковые системы даже расширили robots.txt, включив в него директиву Allow , сопоставление с шаблоном имени файла или папки и расположение XML-карты сайта.
Вот прекрасно выполненный файл robots.txt из SEOmoz :
# Ничего интересного здесь не увидеть, но здесь проходит танцевальная вечеринка: http://www.youtube.com/watch?v=9vwZ5FQEUFg User-agent: * Disallow: / api / user? * Disallow: Карта сайта: http://www.seomoz.org/blog-sitemap.xml Карта сайта: http://www.seomoz.org/ugc-sitemap.xml Карта сайта: http://www.seomoz.org/profiles-sitemap.xml Карта сайта : http://app.wistia.com/sitemaps/2.xml
Если вы не знакомы с robots.txt, обязательно прочитайте эти страницы:
Что robots.txt не делает, так это не пускает файлы в индексы поисковой системы. Единственное, что он делает, - инструктирует поисковиков не сканировать страницы. Имейте в виду, что обнаружение и сканирование являются отдельными. Обнаружение происходит, когда поисковые системы находят ссылки в документах. Когда поисковые системы обнаруживают страницы, они могут добавлять или не добавлять их в свои индексы.
Robots.txt не хранит файлы из индекса поиска!
Убедитесь сами в сайт: permanent.access.gpo.gov ,
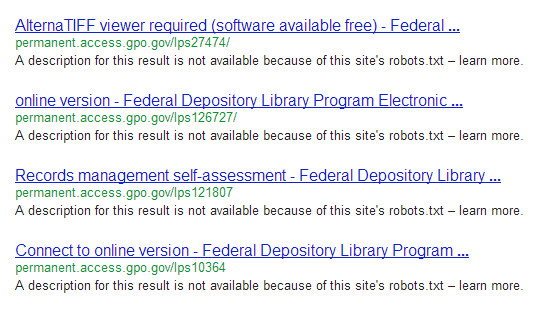
Является ли Robots.txt угрозой безопасности или конфиденциальности?
Использование robots.txt для сокрытия конфиденциальных или личных файлов представляет угрозу безопасности. Мало того, что поисковые системы могут индексировать запрещенные файлы, это все равно что давать карту сокровищ пиратам. Посмотрите сами и посмотрите, что вы узнаете.
Вот файл robots.txt поисковой системы.
User-Agent: * Disallow: / drafts / Disallow: / cgi-bin / Disallow: / gkd / Disallow: / figz / wp-admin / Disallow: / figz / wp-content / plugins / Disallow: / figs / wp-includes / Disallow: / images / 20 / Disallow: / css / Disallow: / * / feed Disallow: / * / feed / rss Disallow: / *?
Я использовал его для поиска Inurl: https: //searchengineland.com/figz , Как видите, я нашел несколько файлов, о которых, вероятно, не должен был знать.
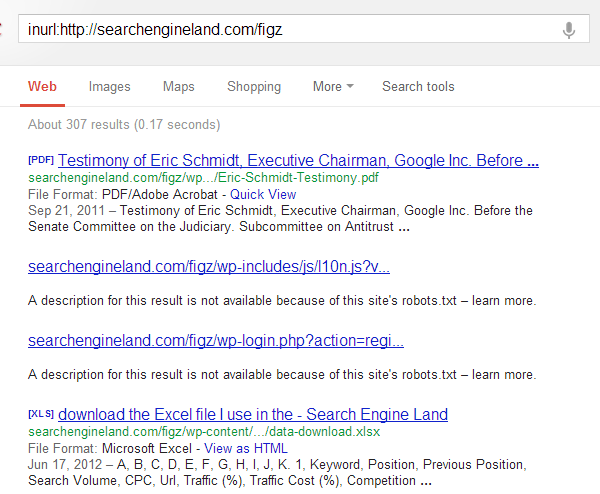
Не волнуйся; если бы я увидел что-то рискованное или чувствительное на Земле поисковых систем, я бы никогда не поделился этим примером. Можете ли вы сказать то же самое о вашем веб-сайте или онлайн-приложении?
Используйте тег <META> роботов, чтобы файлы не попадали в поисковый индекс
Поскольку robots.txt не исключает файлы из поисковых индексов, Google и Bing следуют протоколу, который выполняет именно это, Теги <META> роботов ,
<html> <head> <title> ... </ title> <META NAME = "ROBOTS" CONTENT = "NOINDEX, FOLLOW"> </ head>
Тег <META> роботов содержит две инструкции:
- индекс или noindex
- следовать или nofollow
Index или noindex указывает поисковым системам, индексировать страницу или нет. Когда вы выбираете индекс, они могут или не могут включить веб-страницу в индекс. Если вы выберете noindex, поисковые системы определенно не будут включать его.
Follow or nofollow указывает сканерам, следует ли переходить по ссылкам на странице. Это как добавить отн =»NOFOLLOW» пометить каждую ссылку на странице. Nofollow испаряет PageRank, сырой рейтинг в поисковых системах, передаваемый от страницы к возрасту по ссылкам. Даже если вы не индексируете страницу, вероятно, это плохая идея. Пусть PageRank дойдет до своего окончательного завершения. В противном случае, вы могли бы налить совершенно хороший сок сока.
Если вы хотите исключить страницу из индексов поисковой системы, сделайте это:
<html> <head> <title> ... </ title> <META NAME = "ROBOTS" CONTENT = "NOINDEX, FOLLOW"> </ head>
Там нет остановки плохого поведения
Проблема, с которой вы столкнетесь как с robots.txt, так и с тегом <META> robots, заключается в том, что эти инструкции не могут применять свои директивы. Хотя Google и Bing, безусловно, будут уважать ваши инструкции, кто-то, использующий Screaming Frog, Xenu или их собственный пользовательский сканер сайтов, может просто игнорировать директивы disallow и noindex.
Единственная реальная безопасность - это блокировать личный контент за логином. Если ваш бизнес находится в конкурентном пространстве, он будет сканироваться время от времени, и есть несколько вещей, которые вы можете сделать, чтобы остановить или помешать ему.
И последнее замечание: я не выпускаю здесь кошек из сумки. Пираты и хакеры знают все это. Они знают годами. Теперь и вы тоже.
Мнения, выраженные в этой статье, принадлежат автору гостя и не обязательно относятся к Search Engine Land. Штатные авторы перечислены Вот ,
Об авторе
Txt угрозой безопасности или конфиденциальности?Com/watch?
V=9vwZ5FQEUFg User-agent: * Disallow: / api / user?
Txt угрозой безопасности или конфиденциальности?
Можете ли вы сказать то же самое о вашем веб-сайте или онлайн-приложении?