
- Hidden Frog: Легко пропустити, але потужний, кричала жаба звіти
- Поглиблення з DeepCrawl
- Бонус: запуск DeepCrawl 2.0 скоро
- Наступні кроки: Переконайтеся, що ви перевіряєте ці легкі для пропуску звіти про сканування

Я писав багато в минулому про використання різних інструментів сканування, щоб допомогти з SEO. Причина проста. Виходячи з кількості проведених аудитів, я б сказав, що ви ніколи не знаєте, що відбувається з великим і складним сайтом, поки ви не скануєте його .
Мої два улюблені інструменти для сканування веб-сайтів - DeepCrawl (де я перебуваю на консультативній раді клієнта) і Screaming Frog. Обидва вони відмінні інструменти, упаковані з цінними функціональними можливостями.
Як правило, я використовую DeepCrawl для сканувань на рівні підприємства, тоді як я використовую Screaming Frog на сайтах малого та середнього розміру. Я також використовую обидва разом , оскільки іноді обхід підприємств дає висновки, які вимагають меншого, хірургічного повзання. Таким чином, для мене сума комбінування DeepCrawl з Screaming Frog більше, ніж її частин: 1 + 1 = 3.
Обидва інструменти надають величезну кількість даних, але я виявив, що в тіні є кілька важливих і важливих звітів. У цій посаді, я збираюся швидко охопити дев'ять простих для пропуску звітів сканування, які упаковують серйозні удари SEO. І два з цих звітів є частиною DeepCrawl 2.0, яка має бути випущена найближчим часом (протягом найближчих декількох тижнів). Давайте почнемо.
Hidden Frog: Легко пропустити, але потужний, кричала жаба звіти
Перенаправлення ланцюгів
Більшість SEO-фахівців знають, що вам потрібно переадресовувати старі URL-адреси до своїх нових партнерів при переробці веб-сайтів або міграції CMS. Але я бачив занадто багато людей, які перевіряють початкове перенаправлення 301 і зупиняють їх дослідження. НЕ ЗРАЗУЙТЕ ЦЕ ПОМИЛКА.
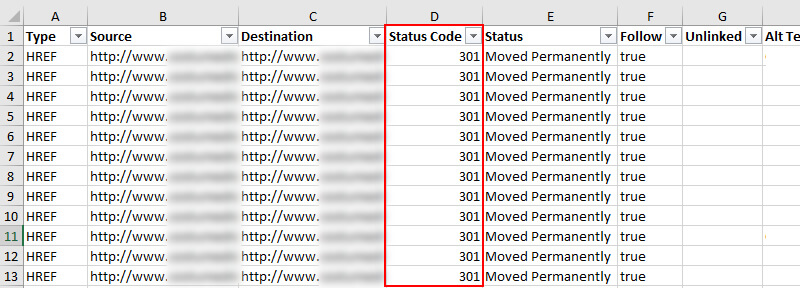
301 може привести до коду відповіді 200 заголовків, що є великим. Але це також може привести до 404, який не є великим. Або це може призвести до іншого 301, або ще п'яти 301s. Або, можливо, це призводить до 500 (помилка програми). Просто тому, що перенаправлення URL 301 не означає, що він правильно вирішується після перенаправлення . Саме там світиться звіт Redirect Chains в Screaming Frog.
Переконайтеся, що у налаштуваннях встановлено прапорець "Завжди слідкувати за перенаправленнями", а потім скануйте ці старі URL-адреси (ті, які потрібно перенаправити).
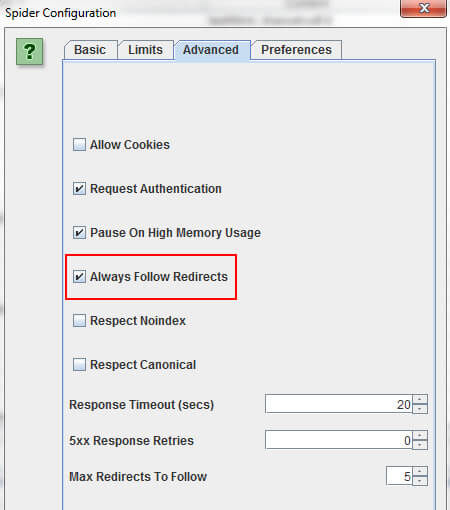
Screaming Frog буде слідувати перенаправленням, потім надасть повний шлях від початкового перенаправлення до 200, 301, 302, 404, 500 і так далі. Щоб експортувати звіт, необхідно натиснути кнопку "Звіти" в головному меню, а потім вибрати "Перенаправити ланцюги".
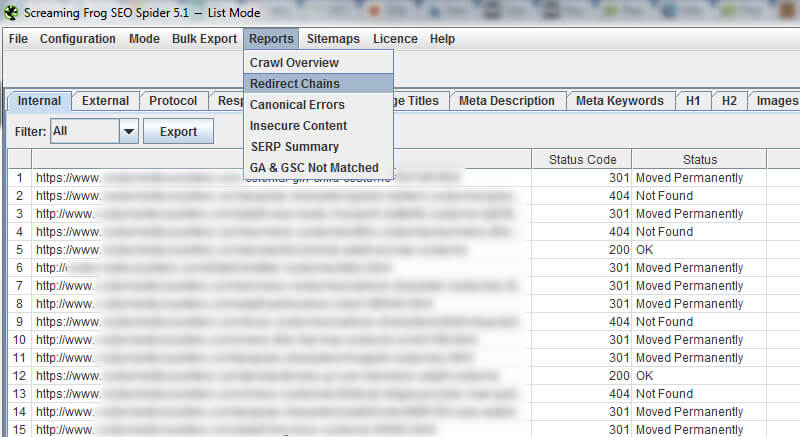
Опинившись у Excel, ви побачите оригінальну URL-адресу, яку перенаправлено, і потім вирішує проблему перенаправлення URL-адреси. І якщо ця друга URL-адреса перенаправляє, ви можете стежити за ланцюгом перенаправлення. Знову ж таки, це дуже важливо знати. Якщо ваш 301s призведе до 404s, то ви можете втрачають рейтинги і трафік зі сторінок, які використовувалися для ранжирування. Не добре.

Небезпечний вміст
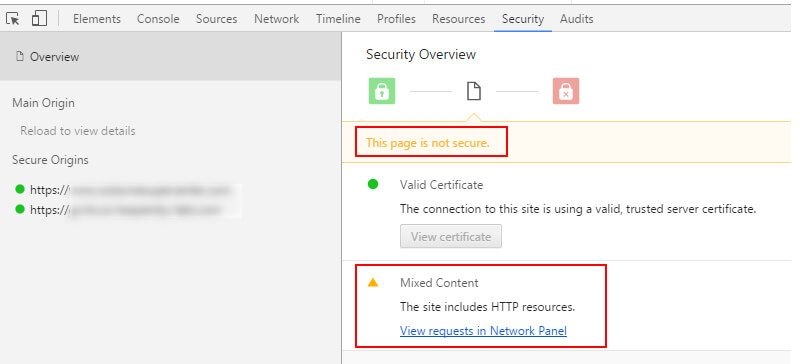
Багато сайтів переходять до HTTPS, коли Google надає тиск. Коли ти перейти до HTTPS існує декілька пунктів для перевірки, щоб переконатися, що міграція обробляється належним чином. Один з цих пунктів полягає в тому, щоб ви не зіткнулися з проблемою невідповідності вмісту. Саме тоді ви поставляєте небезпечні елементи через захищені URL-адреси.
Якщо ви це зробите, ви побачите таку помилку:
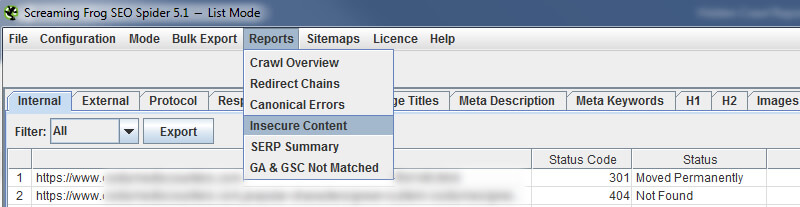
Багато людей цього не знають, але Screaming Frog має звіт, вбудований, який показує небезпечний зміст. Знову перейдіть до спадного списку «Звіти» у головному меню та виберіть «Небезпечний вміст». У звіті буде вказано джерело небезпечного вмісту та URL-адреси HTTPS, які він доставляє.
Після того, як ви запустите звіт після переходу на HTTPS, ви можете експортувати його та надіслати дані розробникам.
Канонічні помилки
Тег канонічної URL-адреси є потужним засобом, щоб переконатися, що пошукові системи розуміють ваші бажані URL-адреси (належні сторінки, які повинні бути проіндексовані). Це може допомогти скоротити кількість дубльованих вмістів, а також об'єднати властивості індексування з декількох URL-адрес до канонічних один.
Але канонічний URL тег також є відмінним способом знищити SEO одним рядком коду . Я бачив багато невдалих реалізацій канонічного тегу протягом багатьох років. І в найгіршому випадку, це може викликати масові проблеми SEO - наприклад, канонізація всього сайту на домашню сторінку або вказівка rel canonical на сторінки, які 404, перенаправлення на 404s і так далі.
Існує багато способів розв'язати канонічну проблему, але проблема для SEO полягає в тому, що вона лежить під поверхнею. Мітка невидима неозброєним оком, що робить її дуже, дуже небезпечною. Отже, Screaming Frog надає звіт про «канонічні помилки», який може допомогти швидко розв'язати ці проблеми. Просто знову зверніться до меню "Звіти" і виберіть "Канонічні помилки".
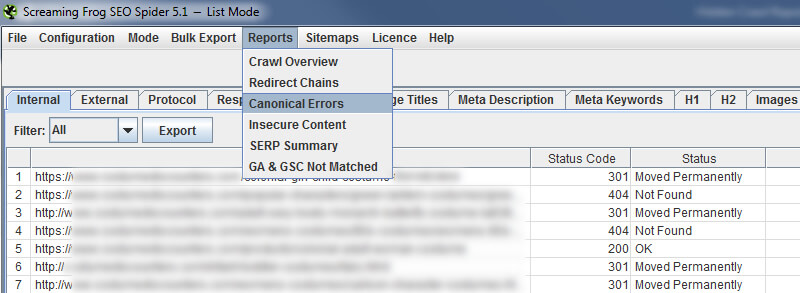
Після експортування звіту ви побачите кожну канонічну помилку, яку Screaming Frog підняла під час сканування. Ви можете бути шоковані тим, що ви знайдете. Доброю новиною є те, що ви можете надіслати звіт вашій команді розробників, щоб вони могли вишукувати, чому ці помилки відбуваються, і вносити необхідні зміни для вирішення основної проблеми.
Поглиблення з DeepCrawl
Пагін: Перші сторінки
Розташування є поширеним для великомасштабних сайтів, особливо для сайтів електронної комерції, які містять категорії з багатьма продуктами.
Але pagination також є заплутаною темою для багатьох SEO, що часто дає неправильне налаштування з точки зору технічного SEO. Від сторінок компонентів noindexing до мікшування noindex і rel наступних / попередніх тегів до інших проблемних комбінацій, ви часто можете надіслати Google дуже дивні сигнали про вашу нумерацію сторінок.
DeepCrawl 1.9 (поточна версія) містить деякі надзвичайно цінні звіти, які можуть допомогти вам вистежити ці проблеми. Наприклад, коли ви скануєте великий і складний сайт, то іноді можна розмістити сторінки в глибині сайту (за межами очевидних областей). У звіті "Перші сторінки" відображатимуться перші сторінки в пагінації (URL-адреси, які містять тег rel = “next”). Це допоможе вам відстежити відправну точку для багатьох випадків нумерації сторінок на широкому веб-сайті.
Ви знайдете набір звітів про розбиття сторінок у DeepCrawl, натиснувши вкладку "Вміст", а потім прокрутіть у нижній частині звіту "Вміст". Ось знімок екрана звіту "Перші сторінки".
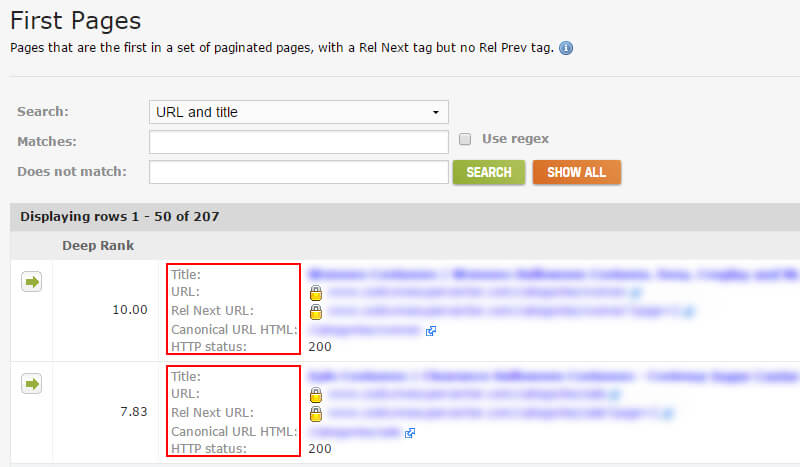
Після того, як ви знайдете розбиття сторінок за допомогою звіту "Перші сторінки", ви можете копати глибше і дізнатися, чи правильно встановлено розбиття сторінок. Сторінки компонентів пов'язані між собою? Чи правильно використовується rel / next? Як щодо rel canonical? Чи не індексуються сторінки компонентів? Чи є вони канонізованими до першої сторінки?
Ви можете дізнатися відповіді на всі ці запитання та багато іншого. Але знову ж таки, потрібно знайти всі примірники нумерації сторінок. Саме там допомагає цей звіт.
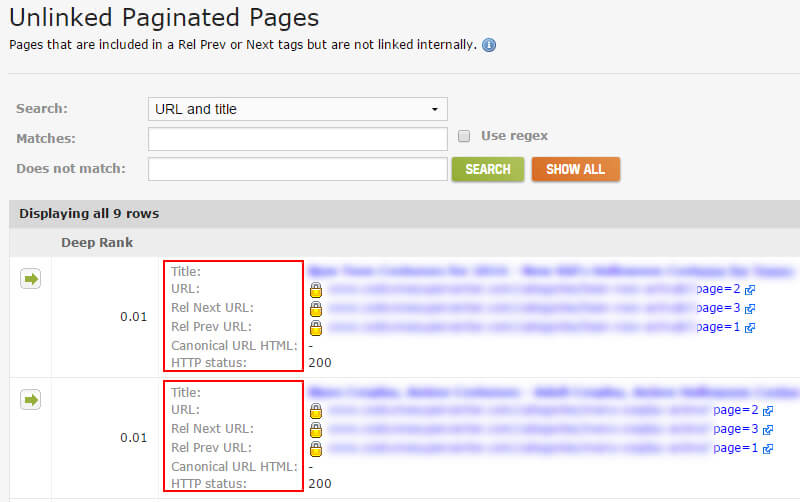
Розбиття сторінок: незв'язані сторінки
Наступний фрагмент головоломки - відстеження сторінок компонентів, які включені в теги rel / next, але не пов'язані між собою на сайті. Пошук цих сторінок може допомогти технічним проблемам SEO. Наприклад, URL-адреси, що містять наступний тег rel, повинні посилатися на наступну сторінку компонента в наборі. Сторінки, що мають відношення rel = ”next” та rel = ”prev”, повинні посилатися на попередню і наступну сторінки. Так далі і так далі.
Якщо ви знайдете rel наступні / попередні теги без пов'язаних між собою URL-адрес, це може сигналізувати про більш глибокі проблеми. Можливо, існуючий код на сайті, який повинен був бути видалений. Можливо, мають бути посилання на сторінки компонентів, але вони не відображаються в коді або на сторінці. Можливо, тут немає “наступної сторінки”, але є ще тег rel = ”next”, який вказує на 404. Знову ж таки, ви ніколи не знаєте, що ви збираєтеся знайти, поки не заринетесь.
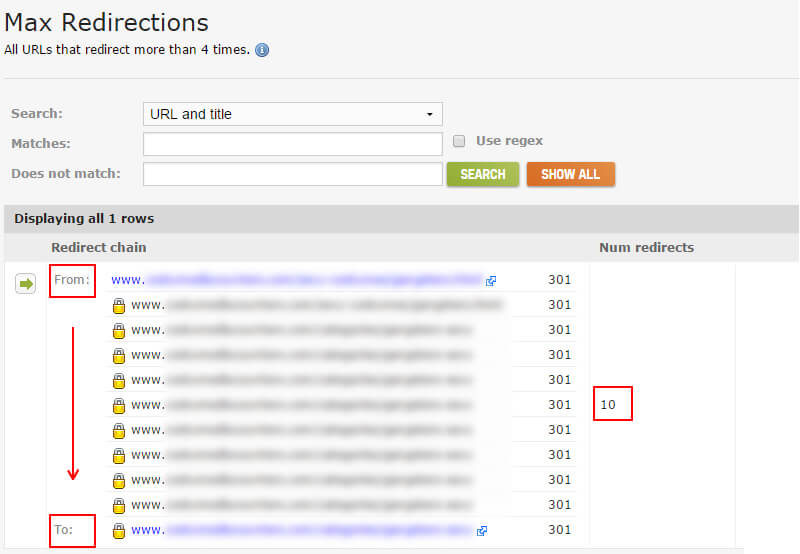
Макс. Перенаправлення
Я згадував раніше, що деякі перенаправляють маргаритку на ще більше переадресацій. І коли це відбувається кілька разів, це потенційно може викликати проблеми, SEO-мудрий. Пам'ятайте, ви повинні переадресовувати один раз на цільову сторінку, якщо це можливо. Як Google Джон Мюллер пояснив , якщо Google бачить більше п'яти переадресацій, він може припинити наступне, і він може спробувати знову під час наступного сканування.
DeepCrawl надає звіт "Max Redirections", який надає всі URL-адреси, які перенаправляють більше чотирьох разів. Це відмінний спосіб легко переглядати та аналізувати ці URL-адреси. І, звичайно, ви можете швидко перейти, щоб виправити ці ланцюги перенаправлення. Звіт "Максимальні перенаправлення" можна знайти у DeepCrawl, клацнувши вкладку "Перевірка" і перейшовши до розділу "Інше".
Сторінки з тегами hreflang (і без)
Hreflang - це чудовий спосіб зв'язати кілька мовних URL-адрес разом. Потім Google може подати правильну версію сторінки в видачах на основі мови користувача.
Але, спираючись на мій досвід, я бачив навантаження на помилки під час аудиту. Наприклад, необхідно включити теги повернення на сторінках, на які посилаються інші сторінки кластера. Отже, якщо ваша сторінка "en" посилається на вашу сторінку "es", то сторінка "es" повинна також посилатися на сторінку "en". Нижче наведено приклад помилок, які не відображаються у консолі пошуку Google.
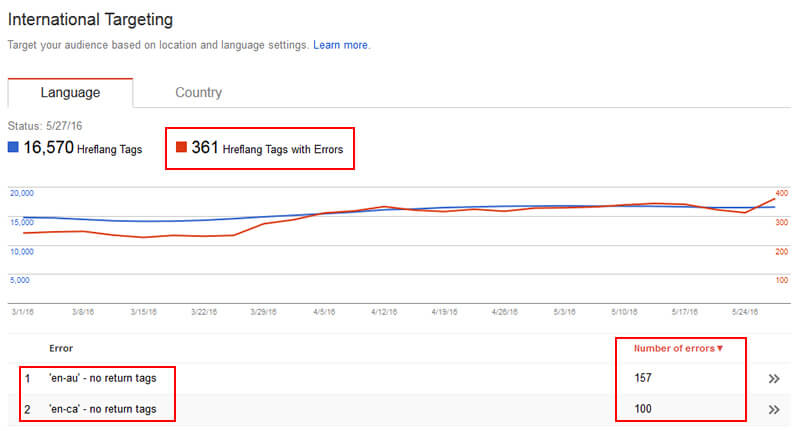
Крім того, існують і інші способи розблокувати теги hreflang, наприклад, надання неправильних кодів мови та країни, неправильне використання x-default і так далі. Таким чином, ви, безумовно, хочете знати всі сторінки, які містять hreflang, щоб ви могли глибше зрозуміти, якщо ці теги налаштовані належним чином.
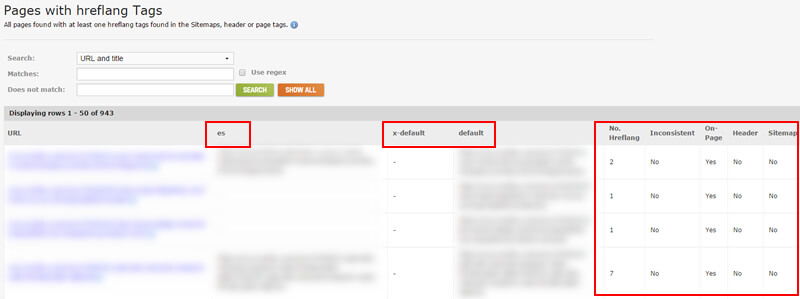
У DeepCrawl є декілька звітів для аналізу hreflang. Найбільш основним, але все ще потужним, є звіт "Мітки з сторінками з hreflang". У ньому будуть перераховані всі сторінки, які містять теги hreflang, надаються всі теги, знайдені на кожній сторінці, і вказується, чи подаються вони в HTML сторінки, через XML-мапи сайту, або доставлені через заголовок відповіді. Ви можете знайти набір звітів hreflang у DeepCrawl, натиснувши вкладку "Перевірка", і прокрутити до розділу, позначеного як "Інше".
Пам'ятайте, що теги на сторінці легше підібрати, оскільки вони знаходяться в коді , але коли hreflang доставляється через заголовок відповіді або в Sitemap, ви не будете знати про це, просто переглядаючи сторінку. Звіт hreflang DeepCrawl відобразить цю інформацію для вас.
Бонус: запуск DeepCrawl 2.0 скоро
Я згадував раніше, що я є частиною консультативної ради клієнта для DeepCrawl. Ну, я тестував нову версію в бета-версії, версія 2.0, і вона близька до запуску. Як частина версії 2.0, є кілька нових і неймовірно цінних звітів. Я доторкнуся до двох з них нижче. Пам'ятайте, що ви не можете отримати доступ до цих звітів у поточній версії (1.9), але ви зможете в 2.0, які повинні бути запущені протягом наступних кількох тижнів.
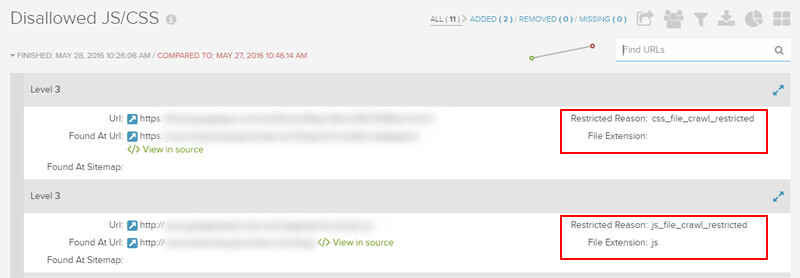
Заборонено JS / CSS
Щоб Googlebot точно відобразив сторінку, він повинен отримати необхідні ресурси (наприклад, CSS і JavaScript). Якщо ці ресурси заблоковано файлом robots.txt, Google не може точно відобразити сторінку, як типовий веб-переглядач. Компанія Google записує, що блокування ресурсів може " пошкодити індексацію сторінок . ”Не добре, щоб сказати найменш.
Використання функції "Вибрати як Google" у Пошуковій консолі Google і вибір "вибірка та візуалізація" - відмінний спосіб перевірити, як Googlebot може відображати окремі сторінки. А як щодо перевірки 50 000 сторінок, 500 000 сторінок, 1 000 000 сторінок або більше? Ну, у DeepCrawl 2.0 з'явився новий звіт, на якому поверхня заборонена ресурсами, такими як JavaScript і CSS, і це відмінний спосіб швидко побачити, які ресурси на сайті блокуються. Тоді ви можете швидко виправити ці проблеми.
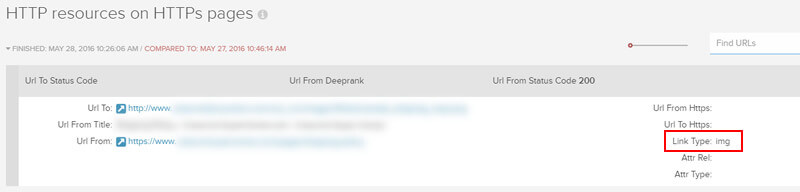
Ресурси HTTP на HTTPS
Є багато сайтів, які беруть участь і переходять до HTTPS. Але є також багато сайтів, які неправильно обслуговують вміст HTTP через HTTPS (що призведе до помилки контенту). DeepCrawl 2.0 дає змогу висвітлити цю проблему через масштабне сканування. Після визначення HTTP-ресурсів, які доставляються на HTTPS, ви можете працювати з розробниками для усунення проблеми.
Наступні кроки: Переконайтеся, що ви перевіряєте ці легкі для пропуску звіти про сканування
Гаразд, тепер у вас є дев'ять додаткових звітів, які можна проаналізувати за межами тих, про які ви могли знати (як в Screaming Frog і DeepCrawl). Звіти, які я висвітлював у цій посаді, надають велику кількість важливих даних, які можуть допомогти вам на поверхні технічних проблем SEO. І ці проблеми можуть перешкоджати вашій діяльності в органічному пошуку. Отже, виповзайте, а потім перевірте ці звіти! Ви ніколи не знаєте, що ви збираєтеся знайти.
Думки, висловлені в цій статті, є думкою автора і не обов'язково є пошуковою землею. Перераховані автори персоналу тут .
Про автора
Сторінки компонентів пов'язані між собою?Чи правильно використовується rel / next?
Як щодо rel canonical?
Чи не індексуються сторінки компонентів?
Чи є вони канонізованими до першої сторінки?
А як щодо перевірки 50 000 сторінок, 500 000 сторінок, 1 000 000 сторінок або більше?