
- Принципи складання семантичного ядра
- Yandex Wordstat - що потрібно враховувати при зборі семядра
- Що необхідно знати і розуміти для успішного використання вордстат
- Оператори вордстат в прикладах
- Оператори лапки і знак оклику - відсів пустушок в Wordstat
- Як швидко прибрати сміття і залишити тільки цільові запити
- Підбір ключовими слів в Яндекс вордстат
- Секретні техніки роботи з вордстат
- Як побачити накрутку пошукового запиту в Wordstat
- Як автоматизувати збір ключових слів в сервісі Яндекса
- Чому така висока частотність у запитів з повторюваними словами?
- Завершуємо складання семантичного ядра
Привіт, шановні читачі блогу KtoNaNovenkogo.ru. Сьогодні я спробую розповісти вам про таке поняття, як семантичне ядро, у всякому разі спробую, бо тема досить специфічна і навряд чи буде всім цікава, хоча ...
У коментарях до статті Самостійне просування сайту мене ніби як попросили (або зробили зауваження, що про це не згадав) написати про підбір ключових слів і виділення цільових запитів в онлайн сервісі Вордстат від Яндекса, що я і спробую зробити в цій публікації.

Якщо спробувати в двох словах описати призначення семантичного ядра, то я б сказав, що це дуже схоже на складання блок схеми перед написанням програми. У ньому ви плануєте ті ключові слова і словосполучення, за якими буде просуватися ваш проект в цілому, а також чітко визначаєте, під які саме пошукові запити будуть оптимізуватися ті чи інші сторінки майбутнього або вже існуючого сайту.
А потім вже по наміченої схемою ви будете планомірно створювати структуру майбутнього сайту і наповнювати його матеріалами, одночасно оптимізуючи їх під заздалегідь намічені ключові. Загалом, працювати над своїм проектом з широко відкритими очима завжди краще ...
Принципи складання семантичного ядра
При складанні семантичного ядра ви не просто будете підбирати слова і фрази, а чітко розділіть їх по тому, наскільки часто їх запрошують у пошукачів і наскільки ці запити підійдуть саме для вашого проекту. Навіщо це потрібно?
По-перше, просуватися по фразам, які нікого не цікавлять, буде марним заняттям, але головне не це. Справа в тому, що організовуючи певним чином внутрішню лінковку сторінок свого майбутнього проекту, ви зможете домогтися збільшення статичного ваги, наприклад, у головної сторінки і у сторінок розділів або категорій. Таким чином, сторінки, які мають великий статичний вага, буде актуально просувати по більш високочастотним пошуковим запитам .
А внутрішні сторінки сайту, статичний вага яких не дуже високий, можна оптимізувати під низькочастотні запити (НЧ), які, як я вже не раз згадував, при вдалому збігу обставин можна просунути практично без залучення зовнішньої оптимізації (покупки зворотних посилань на ці статті).
Але якщо вже ми торкнулися питання частотності запитів, без урахування якого скласти семантичне ядро у нас навряд чи вийде, то я дозволю собі трохи нагадати вам про це і про те, як визначати їх частоту. Отже, всі запити, які користувачі набирають у пошуковому рядку Яндекса, Google або будь-який інший пошукової системи, можна досить умовно розділити на три групи:
- високочастотні (ВЧ)
- середньочастотні (СЧ)
- низькочастотні (НЧ)
Віднести ключову фразу до тієї чи іншої групи можна буде за кількістю таких запитів, що здійснюються користувачами протягом місяця. Але для різних тематик кордону можуть досить суттєво відрізнятися. Справа тут в тому, що нас, по суті, при підборі ключових слів цікавить не частота введення їх користувачами, а то, наскільки важко буде просунутися по ним (чи багато оптимізаторів намагаються робити те ж саме, що і ви).
Тому можна буде ввести ще три градації, які для складання семантичного ядра будуть мати велике значення:
- висококонкурентні (ВК)
- среднеконкурентние (СК)
- нізкоконкурентним (НК)
Але ось визначити конкурентність того чи іншого ключового слова або фрази не завжди виявляється просто. Тому часто для спрощення проводять паралелі і ототожнюють ВК з ВЧ, СЧ з СК, а НЧ З НК. У більшості випадків таке узагальнення буде виправдано, але з будь-якого правила, як відомо, бувають винятки, і в деяких тематиках НЧ можуть виявитися вискоконкурентним, і ви це відразу ж побачите по тому, як складно буде просунутися в ТОП за даними ключовими словами.
Такі колізії можливі в тематиках, де спостерігається надвисока конкуренція і йде боротьба за кожного окремого користувача, витягуючи їх навіть по зовсім низькочастотних запитах. Хоча це може бути притаманне не тільки комерційної тематики. Наприклад, інформаційні сайти по тематиці «WordPress» при складанні семантичного ядра повинні враховувати, що навіть запити з частотністю нижче 100 (ста показів в місяць) можуть бути високонкуренти по тій простій причині, що сайтів з цієї тематики тьма тьмуща, бо навіть такі «тупі дядьки »як я намагаються щось писати по цій тематиці.
Але ми не станемо так глибоко вдаватися в деталі і будемо вважати при складанні семантичного ядра, що конкурентність (скільки оптимізаторів намагаються просунути свої проекти по цьому ключу) і частотність (як часто їх вводять в пошуковий рядок користувачі) знаходяться між собою в прямій залежності. Ну, а частотність тих чи інших ключових слів ми вже якось визначити зуміємо, правда ж?
Для цього можна використовувати кілька сервісів статистики пошукових запитів , Але мені найбільше до душі інструмент Яндекса. Раніше він призначався тільки для користувачів сервісу Яндекс Директ, про який я писав тут , Щоб рекламодавці могли правильно складати тексти своїх контекстних оголошень, враховуючи, які саме слова найчастіше запитують у цього пошукача користувачі.
Але потім доступ до онлайн сервісу підбору ключових слів під назвою Яндекс Вордстат (Wordstat.Yandex.ru) був відкритий для всіх бажаючих, ніж ці самі охочі і скористалися. Ну, а ми чим гірші?
Yandex Wordstat - що потрібно враховувати при зборі семядра
Отже, давайте зайдемо на цей чудо-сервіс від Яндекса, який називається «статистика ключових слів» і розташований за адресою Wordstat.Yandex.ru . Цей сервіс створювався і позиціонується як незамінний інструмент для роботи з Яндекс Директом, а так само при SEO просуванні свого сайту під цю пошукову систему. Але по суті він став найпотужнішим інструментом для аналізу ключових слів в рунеті.
Тому крім свого прямого призначення Вордстат Яндекса з успіхом можна так само використовувати:
- При роботі з Гугл АдВордса
- Для пошуку популярних хештегів в соцмережах
- Для отримання даних про попит на той чи інший товар
- Для побудови структури сайту
- Для пошуку схожих слів
- Для проведення тестування попиту на товари або послуги в іншому регіоні при пошуку нових ринків збуту
- Для аналізу успішності проведення оффлайн реклами, шляхом аналізу частоти згадувань брендових слів
При цьому інтерфейс вордстат, можна сказати, спартанський, але це, мабуть, тільки на краще. Якщо хочете більше, то можна використовувати різні програми для віддаленої роботи з цим сервісом, або встановити плагін типу Yandex Wordstat Assistant в свій браузер.
Після введення Яндексом поділу результатів пошуку в залежності від регіону, у вас з'явилася можливість подивитися частоту введення тих чи інших пошукових запитів для кожного регіону окремо (для цього потрібно буде вибрати регіон, перейшовши на відповідну вкладку).
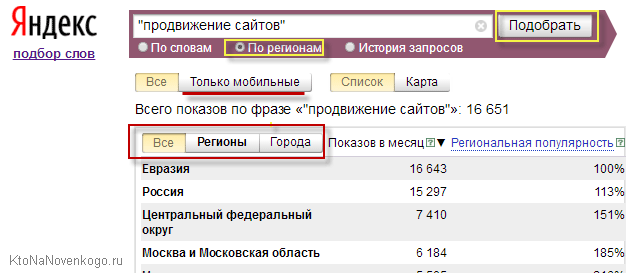
Якщо регіональність вас не хвилює, то має сенс дивитися статистику на першій вкладці без урахування геозалежні. В принципі, це не так вже й важливо на етапі вивчення принципів складання семантичного ядра для сайту. Так само, як і не так давно з'явилася можливість подивитися окремо статистику тільки по мобільним користувачам (що використовують планшети і смартфони). Це може бути актуально в світлі лавинного зростання мобільного трафіку.
У будь-якому випадку, спочатку вам потрібно буде виділити для себе ряд основних ключових слів (масок) по тематиці вашого майбутнього проекту, від яких ми вже почнемо танцювати далі і підбирати за допомогою вордстата Яндекса всі інші кючевікі. Де їх взяти? Ну, просто подумайте чи подивіться на відомих вам конкурентів у вашій ніші (є такий сервіс Серпстат , Який може в цьому допомогти).
Та й проста логіка часто буває дуже корисною. Наприклад, якщо ваш майбутній сайт буде по тематиці «Joomla», то для складання семантичного ядра цілком логічно буде ввести в Яндекс.Вордстат для початку це ключове слово. Логіка проста. Якщо сайт буде по СЕО, то вихідних ключів може бути маса (SEO, просування сайтів, розкрутка, оптимізація і т.п.).
Ну, а ми як приклад візьмемо іншу фразу: «вордстат». Подивимося, що даний онлайн-сервіс скаже нам про самого себе. Тут відразу варто зробити кілька зауважень.
Що необхідно знати і розуміти для успішного використання вордстат
- По-перше, для того, щоб почати отримувати істотний приплив відвідувачів за обраним вами ключу, ваш сайт повинен потрапити в Топ 10 (за першою десяткою життя, на жаль, практично немає) пошукової видачі (серпа - см. тлумачний словник початківця SEO-шника ). А уявіть, що бажаючих (конкурентів) сотні, а то й тисячі. Тому семядро - це тільки необхідна умова успішності сайту, але зовсім не достатня.
- По-друге, крім цього зараз практично для кожного користувача формується своя видача, дещо відмінна від того, що бачить навіть його сусід по поверху. Враховуються переваги і бажання саме цього користувача, якщо Яндексу вдалося їх раніше виявити (ну, і регіон, звичайно ж, якщо запит є геозалежних - наприклад, «доставка піци»). Позиції в цьому плані є «середньою температурою по лікарні» і далеко не завжди приведуть до очікуваного притоку відвідувачів. Хочете побачити справжню картину? користуйтеся режимом «Інкогніто» в вашому браузері .
- По-третє, навіть якщо ви потрапите в Топ 10 видачі (показується більшості ваших цільових користувачів), то число переходів на ваш сайт буде сильно залежати від двох речей: позиції (перша і десята можуть відрізнятися по кликабельности в десятки разів) і привабливості вашого сниппета (Інформації про сторінку вашого сайту, яка відображається у видачі по даному конкретному запиту).
- Обрані вами для просування і формування семантичного ядра запити попросту можуть виявитися пустушками. Хоча пустушки і можна виявити і відсіяти, але новачки досить часто трапляються на цю вудку. Як це побачити і поправити читайте трохи нижче.
- Є така штука, як накрутка пошукових запитів. Мені особисто не приходить в голову кому і навіщо це потрібно, але такі запити зустрічаються. Починаючи з ним просування ви не отримаєте тієї відвідуваності, на яку могли б розраховувати спираючись на дані Яндекс вордстат. Про способи виявлення накруток знову ж читайте трохи нижче.
- Уточнюйте свій регіон (якщо у вас регіональних бізнес або регіональні запити) при перегляді статистики, інакше можете отримати абсолютно не відповідає дійсності картину.
- Обов'язково враховуйте сезонність ваших запитів (якщо вона є) при аналізі результатів просування. У вордстат сезонність добре видно на вкладці «Історія запитів». Не варто враховувати сезонні спади і підйоми, як фактор ваших невдач або успіхів в просуванні.
- Працювати безпосередньо з інтерфейсом сервісу зручно при невеликій кількості запитів, але потім це вже стає «тортурами». Тому головне питання успішного використання Wordstat - автоматизація рутинних операцій. Як і чим автоматизувати буде описано нижче.
- Якщо навчитися правильно користуватися операторами вордстат, то віддачу від нього можна підвищити в рази. Це і лапки, і знак плюс, і розуміння того, що видає цей сервіс при введенні не зовсім звичайних запитів. Про це читайте нижче і в розділі «Секрети ЯнВо»
Налякав? Навіть сам злякався, не дивлячись на те, що по сотням запитів (досить-таки частотним) мій блог знаходиться в Топі (і не в останню чергу завдяки тому, що я майже відразу почав працювати спираючись на семантичне ядро, нехай і в дещо скороченому варіанті - підбираючи ключі під майбутню статтю безпосередньо перед її написанням). Але от якщо б зараз починав (навіть з поточним досвідом), то не повірив би, що «вдасться пробитися». Правда! Вважаю, що по більшій частині пощастило.
Оператори вордстат в прикладах
Отже, давайте детальніше розберемося з двома останніми пунктами - запитами пустушками і накрутити. Чи готові? Ну, тоді понеслася. Почнемо з запитів-пустушок. Пам'ятаєте, який приклад ми використовували трохи вище? Введіть слово вордстат в рядок цього сервісу і натисніть на кнопку "Підібрати".
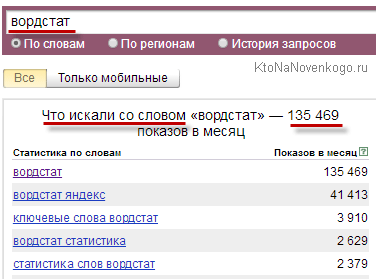
Так ось, треба розуміти, що відображається для цього слова (або будь-який інший фрази) цифра, зовсім не відображає реальну кількість запитів цього ключа. Відображається (увага!) Загальне число фраз запитуваних за місяць, в яких зустрічалося слово «Вордстат», а не кількість запитів, що включають в себе одне це єдине слово (або словосполучення, в разі введення вами ключової фрази в форму Wordstat). Власне, це зрозуміло і з скріншоту - «Пошуковики зі словом ...».
Але в Яндекс вордстат є відповідний інструментарій, який дозволяє відокремити зерна від плевел (виявити пустушки або отримати адекватну реальності інформацію про частотності) і отримати потрібні нам дані. Це різні оператори, які можете додати в свій запит і отримати уточнений результат.

Оператори лапки і знак оклику - відсів пустушок в Wordstat
Як ви можете бачити, основних операторів трохи і головні з них, на мій погляд, цей висновок ключової фрази в лапки і простановка знаку оклику перед словом. Хоча для висококонкурентних тематик може бути актуальним і новий оператор Wordstat у вигляді квадратних лапок. Іноді буває важливо знати, як найчастіше користувачі розставляють слова в потрібному вам запиті (наприклад, «квартиру купити» або все ж «купити квартиру»). Однак, я його поки не використовую.
Отже, оператор вордстат «лапки» дозволить підрахувати кількість вводів у пошуковий рядок Яндекса саме цієї фрази на протязі місяця, але при цьому будуть враховані і підраховані всі можливі її словоформи - інше число, відмінок і т.д. (Наприклад, не будуть враховані запити «Яндекс Вордстат», а тільки «Вордстат» в нашому прикладі). По суті, це те ж саме, що ми розглядали в статті про те, як шукати в Яндексі . Цифра частотності після такої найпростішої операції істотно зменшиться:
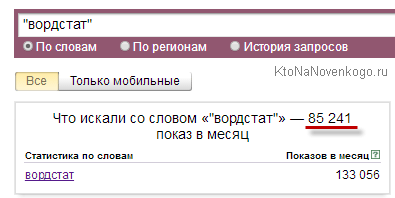
Тобто таку кількість разів за місяць в пошуковий рядок Яндекса користувачі вводили одне єдине слово вордстат у всіх його словоформах (якщо вони взагалі мають місце бути). Звичайно ж, даний запит зовсім не пустушка, а повноцінний ВЧ, але бувають випадки, коли простий висновок фрази в лапки знижує частотність з декількох тисяч до декількох десятків або навіть одиниць (наприклад, пробийте фразу «заробіток 100» в лапках і без). Ось це дійсно була пустушка.
Другий важливий оператор в Wordstat - це знак оклику перед словом, який зобов'яже цей сервіс підраховувати тільки слова саме в такому варіанті написання, в якому ви їх ввели (без урахування словоформ). Як я і припускав, для слова «Joomla» установка оператора знаку оклику ніяких коректив ще не додала, але це тільки через специфіку даного конкретного ключового слова.
Ну, а ось для ключової фрази «просування сайту» різниця буде очевидна і разюча:
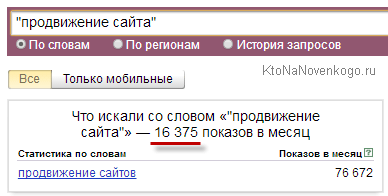
І додамо «!» Перед кожним словом без додавання пробілу:
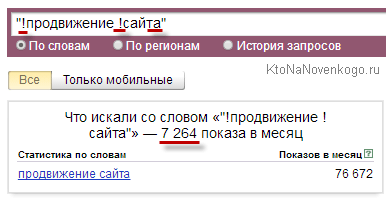
Звідки взялася така різниця в цифрах? Очевидно, що має місце бути запит (и) з тими ж самим ключовими словами, але в інший словоформи, який з'їдає залишилися цифирьки. Для нашого прикладу неважко здогадатися, що це буде множина:
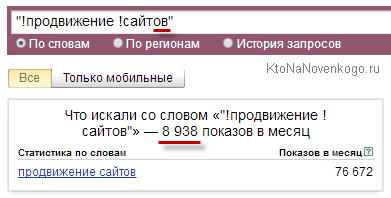
Таким чином ви можете, використовуючи висновок фрази в лапки і встановивши перед кожним із слів знак оклику, отримати вже зовсім інші значення частоти. Таким чином можна не тільки відсіяти пустушки, а й отримати уявлення про словоформах фрази, які бажано буде вживати в тексті частіше, а які рідше (хоча і про синоніми не забувайте). Хоча, особисто я сильної різниці при додаванні знаків оклику не побачу, тому задовольняються простими лапками.
Як швидко прибрати сміття і залишити тільки цільові запити
Є ще один оператор дозволяє відсікти все зайве і побачити реальну частотність фрази. Це «+» перед словом. Він означає, що дане слово у фразі повинно бути присутнім обов'язково. Навіщо це може бути потрібно? Ну, тут вся справа в особливості роботи пошукової системи Яндекс.
За замовчуванням в ранжируванні (а значить і в статистиці Wordstat) не враховуються сполучники, прийменники, вигуки і т.п. слова. Робиться це для спрощення, але найчастіше нас цікавить перспектива просування саме під фразу з приводом або союзом. В цьому випадку і стане в нагоді оператор «плюсик.»
До речі, оператор «мінус» дозволить відразу ж почистити ключові слова від тих, що для вас є нецільовими. Наприклад, такий ось запит до вордстат відразу дасть необхідний результат:
Смартфон (+ до | + з | + на) -Завантажити -ігри-інтернет -мтс -фото
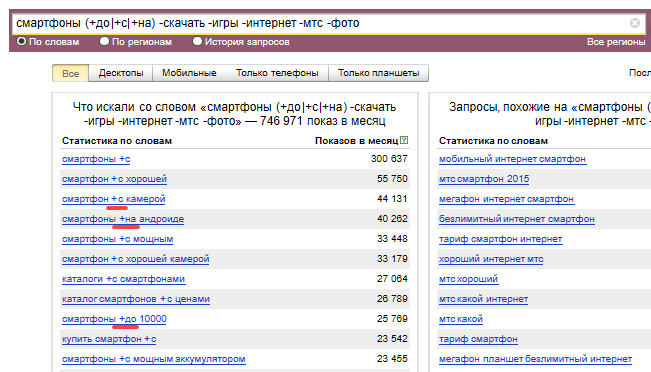
Тут, щоб не повторювати даний запит три рази, застосований оператор «вертикальна риса», який дозволяє зібрати фрази відразу з трьома приводами (до, з, на). Ну, а слова з мінусом (стоп-слова) потрібні для очищення фраз від сміття.
Ось ще приклад використання операторів для тієї ж мети:
пральні (машини | машинки) (samsung | сумісного) -ремонт -помилки -відкликання -коди-відео -запчасти -несправність
Дуже зручно і швидко відсікається непотрібне і економиться час.
Підбір ключовими слів в Яндекс вордстат
Напевно, вам вже стає ясно, що ті базові ключові фрази (маски), які ви здатні сформулювати самі, грунтуючись на майбутньої тематиці вашого проекту, необхідно буде розширити за допомогою вордстат. І тут теж є як би два напрямки в отриманні нових ключових слів для складання повноцінного семантичного ядра.
- По-перше, ви можете скористатися тими розширеними варіантами, які видає Wordstat в лівій колонці свого вікна. Там будуть приведені запити, в яких присутні слова з вашої маски (наприклад, «будівництво», якщо у вашого проекту відповідна тематика). Вони будуть відсортовані за спаданням частоти їх вживання користувачами в пошуковому рядку Яндекса за місяць.
Що тут важливо? Важливо відразу ж виділити ті варіанти розширених ключів, які будуть для вашого проекту цільовими. Цільові - це такі запити, за змістом яких відразу стає ясно, що користувач, що вводить його, шукає саме те, що ви можете йому запропонувати на своєму сайті, який плануєте просувати.
Наприклад, запит «ядро» є надвисокочастотним, але зовсім мені не потрібне, бо це абсолютно не цільовий ключевик для даної публікації. Хіба мало що шукають користувачі вводять його в пошуковому рядку Яндекса, ну вже точно не «семантичне», яке, до речі, буде яскравим прикладом цільового запиту по відношенню до даної статті.
Але вам потрібно вибирати цільові ключі стосовно до всього майбутнього сайту, хоча іноді буває корисно просуватися і за загальними запитам, але це швидше виняток з правил.
Цільові фрази будуть більш низькочастотними і користувачі, що прийшли по ним з видачі, зможуть знайти хоч щось подібне до того, що вони хотіли знайти, а значить не покинуть відразу ж ваш проект, тим самим погіршивши призначений для користувача фактор просування . Та й вам такі відвідувачі дуже важливі, бо вони можуть зробити необхідну вам дію (зробити покупку або замовити послугу).
Думаю, що про відбір саме таких ключових слів з статистики Яндекса далі говорити не потрібно - вам і так все зрозуміло. Єдине «але». Всі фрази з правої колонки вордстат вам знову ж потрібно перевірити на пустушки, а саме, укласти їх в лапки (статистику зі знаками оклику можна буде вже потім подивитися і проаналізувати). Якщо частотність не прагне до нуля, то додаєте її в загашнику.

Ви напевно помітили, що за багатьма фразам список в лівій колонці не обмежується однією сторінкою (там є внизу кнопка «далі»). Максимум, що видає Вордстат - це по-моєму 2000 запитів. І все їх потрібно буде перевірити на пустушки. Впораєтеся? Але ж це тільки одна з багатьох «масок» (початкових ключів) вашого семантичного ядра. Адже там можна і «коні рушити».
Але не турбуйтеся, бо є спосіб автоматизувати підбір ключових фраз в Slovoeb або Key Collector . За посиланням ви знайдете докладну статтю, і якщо після цього ще щось залишиться не зрозуміло, то киньте в мене камінь.
- Другий нюанс при підборі фраз для семантичного ядра полягає в можливості використання так званих асоціацій з статистики Яндекс вордстат. Ці самі асоціативні запити наводяться в правій колонці його основного вікна.
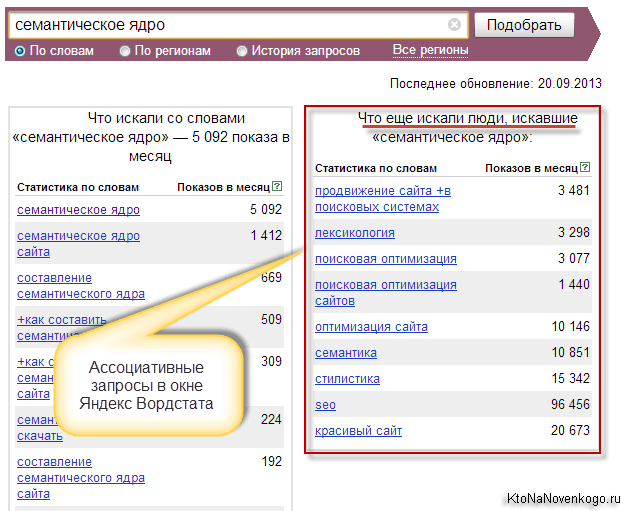
Тут, напевно, важливо уявляти, а як ці самі асоціативні запити в статистиці Яндекса формуються і звідки беруться. Справа в тому, що пошуковик аналізує поведінку користувача, що шукає у нього щось.
Наприклад, якщо користувач після того (або перед тим) як набрати нашу ключову фразу «семантичне ядро» вводив в пошуковий рядок ще який-небудь запит (це називається за одну сесію пошуку), то Яндекс може зробити припущення, що дані запити якось зв'язані між собою.
Якщо така ж асоціативний зв'язок буде спостерігатися і у деяких інших користувачів, то цей задається разом з основним запит буде показаний в правій колонці Wordstat. Ну, а вам залишається тільки скористатися цими даними для розширення семантичного ядра свого сайту.
Всі асоціації матимуть вказівку частотності їх запиту на протязі місяця. Але вона, природно, буде спільною, тобто ще доведеться виявляти пустушки знову ж перевіряючи всі ці фрази взяті в лапки (Slovoeb або Key Collector вам на допомогу - читайте про них за наведеною трохи вище посиланням).
Деякі з асоціативних запитів напевно приходили і вам в голову, але завжди знайдуться і такі, які ви не взяли до уваги. Ну, а чим більше цільових ключових слів буде включати ваше семантичне ядро, тим більша кількість правильних відвідувачів ви зможете залучити на свій сайт при належному проведенні внутрішньої і зовнішньої оптимізації.
Отже, будемо вважати, що грунтуючись на базових масках (ключових слів, явно визначають тематику вашого майбутнього проекту) і можливості Яндекс вордстата, ви змогли набрати достатню кількість фраз для семантичного ядра. Тепер потрібно буде чітко розділити їх за частотою використання.
Секретні техніки роботи з вордстат
Звичайно ж, цей заголовок кілька ярковат, але все ж, саме описані нижче «секрети» можуть допомогти використовувати цей інструмент на всі 200%. Просто якщо цього не враховувати, то можна витратити час, гроші і зусилля даремно.
Як побачити накрутку пошукового запиту в Wordstat
Однак очевидно, що за деякими ключовими словами Wordstat видає неправильну інформацію. Чи пов'язано це з будь-якими варіантами накрутки і як визначити такі пустушки я спробую пояснити. Звичайно ж, перевіряти всі фрази таким чином може бути утомливо і, напевно, тут потрібен просто досвід (чуйку), але це цілком працює.
Особисто я виходжу з тієї передумови, що накручують, як правило, не роками безперервно, а значить відхилення від середнього значення частотності можна буде відстежити на графіку «Історія запиту» (перемикач ховається під рядком введення запиту сервісу Yandex Wordstat). Наприклад, недавно пробивав запити пов'язані з «партнерською програмою» і як раз зіткнувся з накруткою (майже всіх пов'язаних з тематикою ключів).
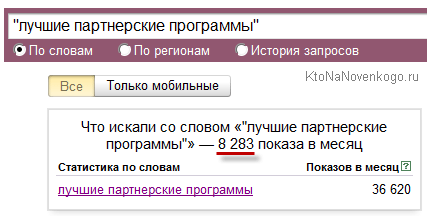
Просто з цими запитами я вже давно працюю і приблизно знаю «розклад». Там ВЧ раз-два та й усе, а тут що ні ключ, то ВЧ. Але досить подивитися на історію частотності цього запиту в Wordstat (лапки тільки не забудьте попередньо прибрати) і все стає ясно (крутити почали з початку літа):
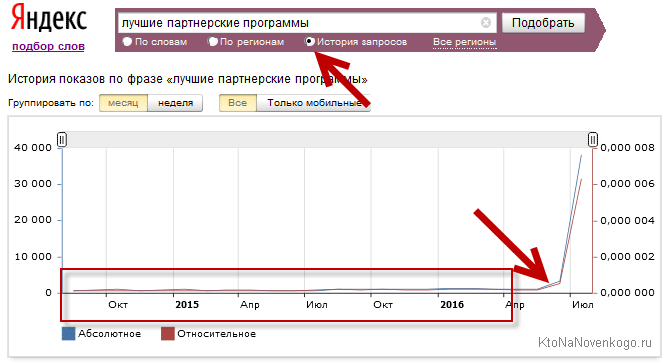
Причому, частотність запиту зросла мало не на два порядки за кілька місяців, а пару років до цього була стабільна і навіть сезонних коливань особливих не змінювалася. Явна накрутка - навіщо не знаю, але крутять всі супутні ключі.
Як автоматизувати збір ключових слів в сервісі Яндекса
В принципі, можна працювати і через вебінтерфейс, але дуже вже це клопітно. Є програми (платні і безкоштовні) відповідні для цієї мети. Є навіть розширення для браузера, які дозволяють трохи перемогти рутину. Давайте їх просто перерахую:
- Yandex Wordstat Assistant - встановлюєте його в свій браузер і при відкритті сторінки вордстат зліва з'явиться модуль цього плагіна.

У нього можна збирати відкриті на сторінці ключові слова (і з лівої, і з правої колонки) за допомогою що з'явилися над кожною колонкою кнопок «Додати все», або додавати по одній фразі клікаючи по плюсик з'явився перед фразами.
Перейшовши на наступну сторінку (або ввівши новий запит) можна буде продовжити збір ключів. З вікна плагіна їх можна скопіювати в буфер обміну і потім вже працювати з ними в зручному редакторі. Так собі автоматизація, але все ж краще, ніж нічого.
- Slovoeb - хороша безкоштовна програма з поганим назвою. Вводите в неї набір «масок» і Парс всю видачу вордстат на потрібну вам глибину. Можна так само зібрати і дані правої по цих запитах, а так же пошукові підказки.
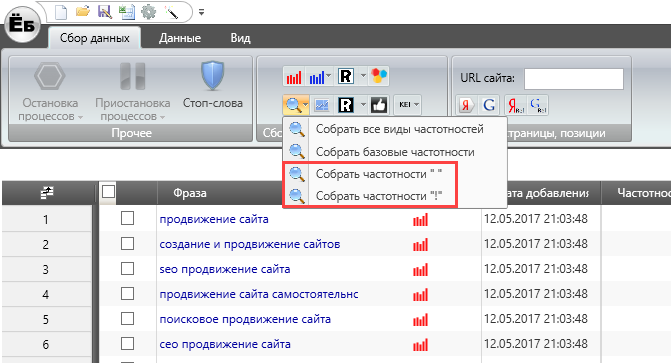
Для всіх зібраних таким чином фраз програма потім сама зможе зібрати частотність (в лапках, або в лапках і зі знаком оклику). Дуже зручно, безкоштовно, але сильно медлленно. Частотність для тисяч фраз програма буде збирати годинами.
- Key Collector - платна версія попередньої програми (не дуже дорога, тому мною вже давно придбана).
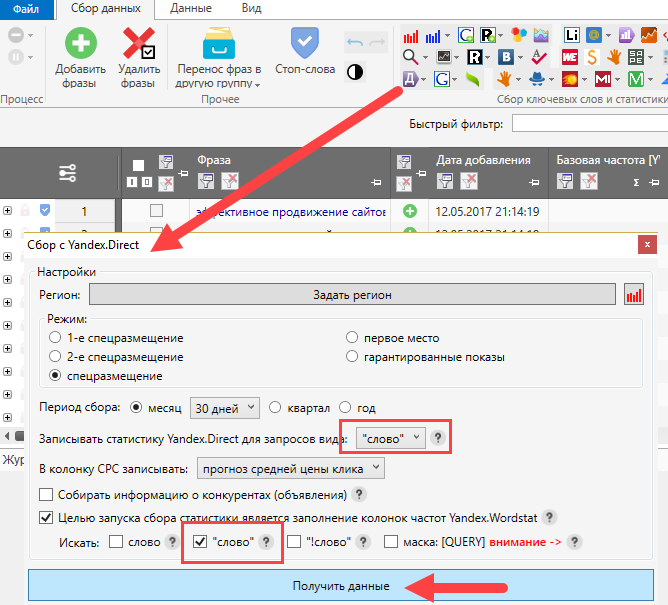
Key Collector має багато додаткових можливостей, але особисто я використовую в основному тільки швидкий збір точної частотності. Робить він це дуже швидко (тисячі запитів на лічені хвилини).
Чому така висока частотність у запитів з повторюваними словами?
Якщо ви вже більш-менш занурилися в питання складання семядра і багато Спарс запитів в Вордестате, то напевно зустрічали дивні запити з повторюваними словами, у яких чомусь висока частотність навіть при їх укладанні в лапки і виставленні знаків оклику перед словами.
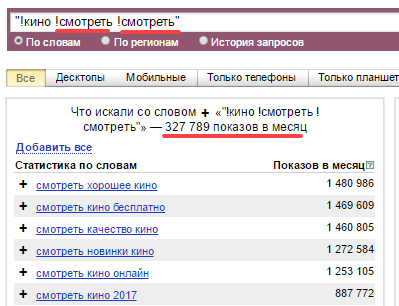
Навіть якщо ще кілька разів додати «дивитися», то частотність все одно залишиться практично такою ж високою. Так що ж, вірити Яндексу і оптимізувати статті під таку маячню? Ні в якому разі. Це ще один вид «пустушки». Насправді, Wordstat сприймає тільки одне з повторюваних слів, а от інші «подумки» замінює іншими можливими словами з такою ж кількістю знаків. Загалом, незважаючи на великі цифри звертати увагу на запити з повторюваними словами не варто. Це фантом.
Завершуємо складання семантичного ядра
Як я говорив трохи вище, ми будемо вважати ВЧ за замовчуванням і ВК, а значить для просування по ним потрібно вибирати такі сторінки свого сайту, які будуть мати найбільший статичну вагу. цей самий статичну вагу або PageRank набирається за рахунок вхідних посилань на цю сторінку.
Важливо розуміти, що при його розрахунку не враховується вміст анкора посилання і не важливо те, зовнішня вона або внутрішня. Детальніше про статичний і динамічний ваги, а також про анкор читайте за ПОСИЛАННЯ.
Т.ч. для просування по самим високочастотним запитам (зі складеного семантичного ядра) найбільш підходить головна сторінка, бо на неї, як правило, будуть вести посилання з усіх інших сторінок вашого ресурсу (при звичайній структурі), а також і більшість зовнішніх посилань, особливо отриманих природним чином . Так що статичну вагу головною для більшості ресурсів буде найвищим (раніше це можна було зрозуміти за показаннями тулбарного значення Google PageRank, яке для неї буде завжди вище, ніж, ніж для внутрішніх, але зараз Гугл вирішив перестати з нами ділитися цією інформацією).
при ранжируванні сайтів у видачі пошукові системи при інших рівних умовах (однаковій якості внутрішньої і зовнішньої оптимізації) вище поставлять ту сторінку, чий статичну вагу більше. Тому, якщо ви виберете для просування по ВЧ внутрішню сторінку (зі свідомо нижчими статвесом), то конкуренти будуть мати перед вами перевага, в разі просування ними за тими ж ключовими словами, але вже головної сторінки свого сайту. Хоча, найкращим способом буде аналіз Топ 10 по потрібному вам ключевику на предмет кількості головних, які беруть участь в ранжируванні (це, до речі, побічно свідчить про конкурентності запиту).
Якщо в структурі внутрішньої перелинковки вашого майбутнього проекту будуть передбачені і інші сторінки з великим статичним вагою (розділи, категорії і т.п.), то в семантичному ядрі потрібно буде відзначити їх як потенційних кандидатів на оптимізацію під більш-менш високо- і середньо частотні запити з підібраних вами.
Таким чином ви зможете використовувати з користю особливості розподілу статичного ваги на вашому сайті і підібрати відповідно до цього найбільш підходящі по частотності запити для кожної зі сторінок, тобто скласти повністю семантичне ядро: підібрати пари запит - сторінка.
Однак, при оптимізації сторінки під просування по ВЧ або СЧ ключовою фразою, ви можете додати ще і більш низькочастотний ключевик, який буде отримуватися шляхом розведення основного ключа. Але знову ж таки, не всі ключі можна зробити сусідами на одній посадкової сторінці. Зрозуміти, які можна використовувати разом, а які не можна, вам допоможе аналіз ваших прямих конкурентів в Топ 10 по основній ключовою фразою. Якщо вони в Топі, то значить пошуку їх варіант семядра припадає до душі.
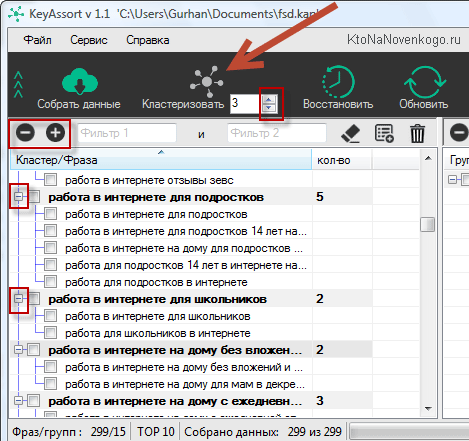
Однак, легко сказати, а важко зробити. Спробуйте пробити видачу по сотням (тисячам) запитів з вашого попереднього семантичного ядра на предмет їх сумісності або несумісності. Тут вже точно «коні можна зрушити». Однак, я і тут прийду вам на допомогу, давши посилання на детальну публікацію про розподіл по сторінках (кластеризацию) запитів з семядра . Реально все спрощує маленька програмка.
При зовнішньої оптимізації (закупівлю та простановке посилань з потрібними анкорами) потрібно знову ж враховувати створене семантичне ядро і проставляти беклінки з урахуванням тих ключових слів, під які оптимізувалася дана сторінка вашого сайту. Не забудьте, що в епоху Минусинска і Пінгвіна беклінк з прямим входженням краще ставити один, але з дуже жирного і тематичного сайту, а «разбавкі» безанкорамі, назвами статті і т.п. робити варто побільше.
На практиці ваше семантичне ядро буде представляти, напевно, досить розгалужену схему сторінок з підібраними для них ключовими словами, під які вони будуть оптимізовані і просуватися. Там же буде промальована схема внутрішньої перелинковки для накачування потрібних сторінок статичним вагою.
Загалом, буде включено і розглянуто всі що тільки можна, залишиться лише почати будувати (або переробляти) сайт за даним проектом (семантичному ядру). Особисто я останнім часом завжди дотримуюся правила про попереднє його складанні, бо працювати наосліп може виявитися не рентабельним заняттям - сили витрачу, а ті, кому матеріал буде цікавий і корисний, так його і не знайдуть ні в Яндексі, ні в Гуглі ...
Якщо говорити про це блозі, то перед написанням статті я обов'язково лізу в Вордстат і дивлюся, як формулюють свої питання користувачі по тій тематиці, про яку планую писати. Тим самим я з більшою ймовірністю знайду свого читача, який при вдалій публікації може стати і постійним. Від цього нікому не погано, хіба що тільки трохи часу витратити доводиться.
Ну, а в разі проекту за новою для вас тематиці, і особливо, якщо ви початківець оптимізатор, складання подібного ядра і підбір відповідних ключових слів зможе вам істотно допомогти і дозволить уникнути зайвих помилок. Тим не менш, не у всіх є час і сили на проведення подібної роботи, але робити її все одно потрібно обов'язково. Однак, якщо є попит, то буде і пропозиція. Завжди знайдуться люди, які готові будуть зробити це за вас, інша справа, що вони можуть виявитися не завжди чесними і виконавчими.
Удачі вам! До швидких зустрічей на страницах блогу KtoNaNovenkogo.ru
Збірки по темі
Використову для заробітку
Навіщо це потрібно?Ну, а частотність тих чи інших ключових слів ми вже якось визначити зуміємо, правда ж?
Ну, а ми чим гірші?
Де їх взяти?
Хочете побачити справжню картину?
Чи готові?
Пам'ятаєте, який приклад ми використовували трохи вище?
Навіщо це може бути потрібно?
Що тут важливо?
Впораєтеся?