
- Robots.txt карацей Файл robots.txt ўтрымлівае дырэктывы для пошукавых сістэм, якія вы можаце выкарыстоўваць,...
- Тэрміналогія вакол файла robots.txt
- Чаму вы павінны клапаціцца аб файле robots.txt?
- прыклад
- Ваш robots.txt працуе супраць вас?
- Агент карыстальніка ў robots.txt
- Disallow ў robots.txt
- прыклад
- Дазволіць у robots.txt
- прыклад
- Прыклад супярэчлівых дырэктыў
- Асобная лінія для кожнай дырэктывы
- Выкарыстоўваючы сімвал *
- прыклад
- Выкарыстоўваючы канец URL $
- прыклад
- Карта сайта ў файле robots.txt
- прыкладаў
- прыклад 1
- прыклад 2
- Абыход затрымкі ў robots.txt
- прыклад:
- Калі выкарыстоўваць файл robots.txt?
- Найлепшая практыка для файла robots.txt
- парадак старшынства
- прыклад
- прыклад
- Толькі адна група дырэктыў на робата
- Будзьце як мага больш канкрэтным
- прыклад:
- Дырэктывы для ўсіх робатаў, а таксама уключаючы дырэктывы для канкрэтнага робата
- прыклад
- Файл robots.txt для кожнага (суб) дамена
- прыкладаў
- Супярэчлівыя рэкамендацыі: robots.txt супраць Google Search Console
- Кантралюйце свой файл robots.txt
- Як вы ведаеце, калі ваш robots.txt змены?
- Не выкарыстоўвайце NoIndex ў файле robots.txt
- Прыклады файла robots.txt
- Усе робаты могуць атрымаць доступ да ўсяго
- Усе робаты не маюць доступу
- Усе боты Google не маюць доступу
- Усе боты Google, навіны Googlebot акрамя не маюць доступу
- Googlebot і Slurp не маюць доступу
- Усе робаты не маюць доступу да двух каталогах
- Усе робаты не маюць доступу да аднаго канкрэтнаму файлу
- Googlebot не мае доступу да / адмін / і Slurp не мае доступу да / прыватных /
- Robots.txt для WordPress
- Якія абмежаванні robots.txt?
- Старонкі працягваюць з'яўляцца ў выніках пошуку
- кэшаванне
- памер файла
- Часта задаюць пытанні аб robots.txt
- 1. Ці будзе з дапамогай файлаў robots.txt, каб пошукавыя сістэмы, паказваючы забароненыя старонкі ў...
- 2. Ці павінен я быць асцярожным з дапамогай файлаў robots.txt?
- 3. Ці з'яўляецца гэта незаконным ігнараваць robots.txt, калі выскрабанне вэб-сайт?
- 4. У мяне няма файла robots.txt. Ці будуць пошукавыя сістэмы па-ранейшаму сканаваць мой сайт?
- 5. Ці магу я выкарыстаць NoIndex замест Disallow ў файле robots.txt?
- 6. Якія пошукавыя сістэмы паважаюць файл robots.txt?
- 7. Як я магу прадухіліць пошукавыя сістэмы з вынікаў пошуку індэксацыі старонак на маім сайце WordPress?
Robots.txt карацей
Файл robots.txt ўтрымлівае дырэктывы для пошукавых сістэм, якія вы можаце выкарыстоўваць, каб пошукавыя сістэмы ад поўзання асобных частак вашага сайта.
Пры рэалізацыі robots.txt, захоўвайце наступныя лепшыя практыкі ў выглядзе:
- Будзьце асцярожныя пры унясенні змяненняў у файл robots.txt: гэты файл мае патэнцыял, каб зрабіць вялікія часткі вашага сайта недаступнага для пошукавых сістэм.
- Файл robots.txt павінен знаходзіцца ў каранёвым каталогу вашага сайта (напрыклад, http://www.example.com/robots.txt).
- Файл robots.txt сапраўдны толькі для поўнага дамена ён знаходзіцца на, у тым ліку пратаколу (HTTP ці HTTPS).
- Розныя пошукавыя сістэмы інтэрпрэтуюць дырэктывы па-рознаму. Па змаўчанні, першая дырэктыва адпаведнасці заўсёды перамагае. Але, з дапамогай Google і Bing, спецыфічнасць перамагае.
- Пазбягайце выкарыстанне дырэктывы поўзаць затрымкі для пошукавых сістэм як мага больш.
Што такое файл robots.txt?
Файл robots.txt паведамляе пошукавым сістэмам правілы вашага сайта ўцягнутасці.
Пошукавыя сістэмы рэгулярна правяраць файл robots.txt вэб-сайта, каб убачыць, калі ёсць якія-небудзь інструкцыі для абыходу вэб-сайта. Мы называем гэтыя інструкцыі «дырэктыву».
Калі няма файла robots.txt прысутнічае ці не не ўжываюцца дырэктыў, пошукавыя сістэмы будуць сканаваць ўвесь сайт.
Хоць усе асноўныя пошукавыя сістэмы паважаюць файл robots.txt, пошукавыя сістэмы могуць ігнараваць (часткі) ваш файл robots.txt. У той час як дырэктывы ў файле robots.txt з'яўляюцца сігналам для пошукавых сістэм, важна памятаць, файл robots.txt ўяўляе сабой набор дадатковых дырэктыў для пошукавых сістэм, а не мандат.
Тэрміналогія вакол файла robots.txt
Файл robots.txt з'яўляецца рэалізацыяй стандарту выключэнняў для робатаў або таксама называюць пратаколам робатаў выключэнні.
Чаму вы павінны клапаціцца аб файле robots.txt?
Файл robots.txt адыгрывае істотную ролю з пошукавай аптымізацыі (SEO) пункту гледжання. Гэта кажа пошукавым сістэмам, як яны могуць найлепшым чынам сканаваць ваш сайт.
Выкарыстанне файла robots.txt можна прадухіліць пошукавых сістэм ад доступу да пэўных частках вашага сайта, прадухіліць дубляванне кантэнту і дае пошукавым сістэмам карысныя парады аб тым, як яны могуць сканаваць ваш сайт больш эфектыўна.
Будзьце асцярожныя пры унясенні змяненняў у файл robots.txt , хоць: гэты файл мае патэнцыял , каб зрабіць вялікія часткі вашага сайта недаступнага для пошукавых сістэм.
прыклад
Давайце паглядзім на прыклад, каб праілюстраваць гэта:
Вы працуеце сайт электроннай камерцыі, і наведвальнікі могуць выкарыстоўваць фільтр для хуткага пошуку з дапамогай вашай прадукцыі. Гэты фільтр стварае старонкі, якія ў асноўным паказваюць такое ж змест, як гэта робяць іншыя старонкі. Гэта працуе выдатна падыходзіць для карыстальнікаў, але блытае пошукавыя сістэмы, паколькі яна стварае дубляваць змест , Вы не хочаце, каб пошукавыя сістэмы праіндэксаваць гэтыя адфільтраваць старонкі і марнаваць свой каштоўны час на гэтых URL-адрасоў з адфільтраваным зместам. Для гэтага, вы павінны ўсталяваць правілы Disallow таму пошукавыя сістэмы не маюць доступу да гэтых адфільтраваць старонкі прадукту.
Прадухіленне дублявання кантэнту таксама можа быць зроблена з дапамогай кананічны URL ці мета-тэг робаты, аднак яны не вырашаюць дазволіць пошукавым машынам толькі сканаваць старонкі, якія маюць значэнне. Выкарыстоўваючы кананічны URL або мета робатаў тэг не будзе перашкаджаць пошукавых сістэм сканаванне гэтых старонак. Гэта толькі , каб пошукавыя сістэмы , паказваючы гэтыя старонкі ў выніках пошуку. Так як пошукавыя сістэмы абмежаваць час абыходу вэб-сайт , На гэты раз павінен быць марнаваць на старонках, якія вы хочаце, каб з'явіцца ў пошукавых сістэмах.
Ваш robots.txt працуе супраць вас?
Няправільна ўсталяваны файл robots.txt можа быць стрымліваючы прадукцыйнасць SEO. Праверце, ці з'яўляецца гэта месца для вашага сайта прама зараз!
Прыклад таго, што просты файл robots.txt для WordPress сайта можа выглядаць наступным чынам:
User-Agent: * Disallow: / WP-адміністратара /
Растлумачым анатомію файла robots.txt на аснове прыведзенага вышэй прыкладу:
- User-агент: агент карыстальніка паказвае на якія пошукавыя сістэмы дырэктывы, якія ідуць прызначаныя.
- *: Гэта паказвае на тое, што дырэктывы прызначаныя для ўсіх пошукавых сістэм.
- Disallow: гэта дырэктыва паказвае на тое, што змесціва не даступна для агента карыстальніка.
- / WP-адміністратара /: гэта шлях, які недаступны для агента карыстальніка.
У выніку: У гэтым файле robots.txt кажа ўсё пошукавыя сістэмы, каб застацца па-за / WP-адміністратара / каталога.
Агент карыстальніка ў robots.txt
Кожная пошукавая сістэма павінна ідэнтыфікаваць сябе з агентам карыстальніка. робаты Google, ідэнтыфікуюць сябе як Googlebot, напрыклад, робаты, як сёрбаць і Бінг робата як BingBot і гэтак далей Yahoo.
Запіс агента карыстальніка вызначае пачатак групы дырэктыў. Усе дырэктывы паміж першым агентам карыстальніка і наступнай запісам агента карыстальніка, разглядаюцца ў якасці дырэктывы для першага агента карыстальніка.
Дырэктывы могуць прымяняцца да канкрэтных агентам карыстальніка, але яны таксама могуць быць дастасавальныя да ўсіх агентам карыстальніка. У гэтым выпадку выкарыстоўваецца падстаноўныя: User-Agent: *.
Disallow ў robots.txt
Вы можаце сказаць, пошукавыя сістэмы не атрымаць доступ да некаторых файлаў, старонкі або раздзелы сайта. Гэта робіцца з дапамогай дырэктывы Disallow. Дырэктыва Disallow варта шляху, які не павінен быць доступ. Калі шлях не вызначаны, дырэктыва ігнаруецца.
прыклад
User-Agent: * Disallow: / WP-адміністратара /
У гэтым прыкладзе ўсе пошукавыя сістэмы кажуць не атрымаць доступ да / WP-адміністратара каталога /.
Дазволіць у robots.txt
Дырэктыва Allow выкарыстоўваюцца для процідзеяння дырэктывы Disallow. Дырэктыва Allow падтрымліваецца Google і Bing. Выкарыстанне Allow і Disallow дырэктывы разам вы можаце паведаміць пошукавым сістэмам, яны могуць атрымаць доступ да пэўнага файла або старонкі ў каталогу, які ў адваротным выпадку недазволенай. Дырэктыва Allow ідуць шляху, якія могуць быць даступныя. Калі шлях не вызначаны, дырэктыва ігнаруецца.
прыклад
User-Agent: * Allow: /media/terms-and-conditions.pdf Disallow: / СМІ /
У прыведзеным вышэй прыкладзе ўсе пошукавыя сістэмы не могуць атрымаць доступ да / СМІ / каталог для файла /media/terms-and-conditions.pdf выключэннем.
Важна: пры выкарыстанні Дазволіць і Забараніць дырэктывы разам, пераканайцеся, што не выкарыстоўваць групавыя сімвалы, так як гэта можа прывесці да супярэчлівым дырэктывам.
Прыклад супярэчлівых дырэктыў
User-Agent: * Allow: / Каталог Disallow: /*.html
Пошукавыя сістэмы не будуць ведаць, што рабіць з URL http://www.domain.com/directory.html. Пакуль незразумела, ім яны дазволены доступ.
Асобная лінія для кожнай дырэктывы
Кожная дырэктыва павінна быць на асобнай радку, інакш пошукавыя сістэмы могуць заблытацца пры аналізе файла robots.txt.
Прыклад няправільнага файла robots.txt
Прадухіліць файл robots.txt, як гэта:
User-Agent: * Disallow: / каталог-1 / Disallow: / каталог-2 / Disallow: / каталог-3 /
Выкарыстоўваючы сімвал *
можа падстаноўных быць выкарыстана не толькі для вызначэння агента карыстальніка, ён можа таксама выкарыстоўвацца для супастаўлення URL-адрасоў. Падстаноўных падтрымліваецца Google, Bing, Yahoo і Ask.
прыклад
User-Agent: * Disallow: / *?
У прыкладзе вышэй за ўсіх пошукавых сістэм не дазволены доступ да URL, якія ўключаюць у сябе знак пытання (?).
Выкарыстоўваючы канец URL $
Для таго, каб паказаць канец URL, вы можаце выкарыстоўваць знак даляра ($) у канцы шляху.
прыклад
User-Agent: * Disallow: /*.php$
У прыведзеным вышэй прыкладзе пошукавых сістэм не могуць атрымаць доступ да ўсіх URL, якія заканчваюцца на .php. URL-адрасы з параметрамі, напрыклад https://example.com/page.php?lang=en не будзе адмоўлена, паколькі URL не сканчаецца пасля .php.
Карта сайта ў файле robots.txt
Нягледзячы на тое, што файл robots.txt быў вынайдзены , каб паведаміць пошукавым сістэмам , якія старонкі ня поўзаць, файл robots.txt можа таксама выкарыстоўвацца , каб паказаць пошукавыя сістэмы ў XML карты сайта. Гэта падтрымліваецца Google, Bing, Yahoo і Ask.
XML карта сайта павінна быць спасылка як абсалютны URL. URL не павінен быць на тым жа хасце, што і файл robots.txt. Спасылка на XML карты сайта ў файле robots.txt з'яўляецца адным з лепшых практык, мы раім вам заўсёды, нават калі вы ўжо прадставілі свой XML карты сайта ў Google Search Console або інструменты Bing для вэб-майстроў. Памятаеце, што ёсць больш пошукавых там.
Звярніце ўвагу, што можна спасылацца на некалькі сайтмепов XML ў файле robots.txt.
прыкладаў
Некалькі XML Sitemaps:
User-Agent: * Disallow: / WP-адміністратара / Карта сайта: Карта сайта https://www.example.com/sitemap1.xml: https://www.example.com/sitemap2.xml
Прыведзены вышэй прыклад кажа ўсім пошукавым сістэмам доступу да каталога / WP-адміністратара / і што ёсць два XML Sitemaps, якія могуць быць знойдзены ў https://www.example.com/sitemap1.xml і https: //www.example .com / sitemap2.xml.
Адзіны XML карта сайта:
User-Agent: * Disallow: / WP-адміністратара / Карта сайта: https://www.example.com/sitemap_index.xml
Прыведзены вышэй прыклад кажа ўсім пошукавым сістэмам, каб атрымаць доступ да тэчцы / WP-адміністратара / і што XML-карта сайта можна знайсці на https://www.example.com/sitemap_index.xml.
Каментары папярэднічаюць # і альбо могуць быць размешчаны ў пачатку радка або пасля дырэктывы па адной і той жа лініі. Усе пасля # ігнаруецца. Гэтыя каментары прызначаныя толькі для людзей.
прыклад 1
# Не дазваляць доступ да / WP-адміністратара / каталог для ўсіх робатаў. User-Agent: * Disallow: / WP-адміністратара /
прыклад 2
Агент карыстальніка: * #Applies ўсім робатам Disallow: / WP-адміністратара / # Не дазваляць доступ да / смецце-адмін / каталог.
Прыведзеныя вышэй прыклады звязваюцца тое ж самае.
Абыход затрымкі ў robots.txt
Дырэктыва Crawl-затрымка з'яўляецца неафіцыйнай дырэктыва выкарыстоўваецца для прадухілення перагрузкі сервераў занадта шмат запытаў. Калі пошукавыя сістэмы могуць перагрузіць сервер, дадаўшы Crawl затрымку ў свой файл robots.txt толькі часовае рашэнне. Факт пытання, ваш сайт працуе на беднай асяроддзі хостынгу, і вы павінны выправіць гэта як мага хутчэй.
Дарэчы пошукавыя сістэмы апрацоўваць Crawl затрымкі адрозніваецца. Ніжэй мы разгадаем, як асноўныя пошукавыя сістэмы справіцца з гэтым.
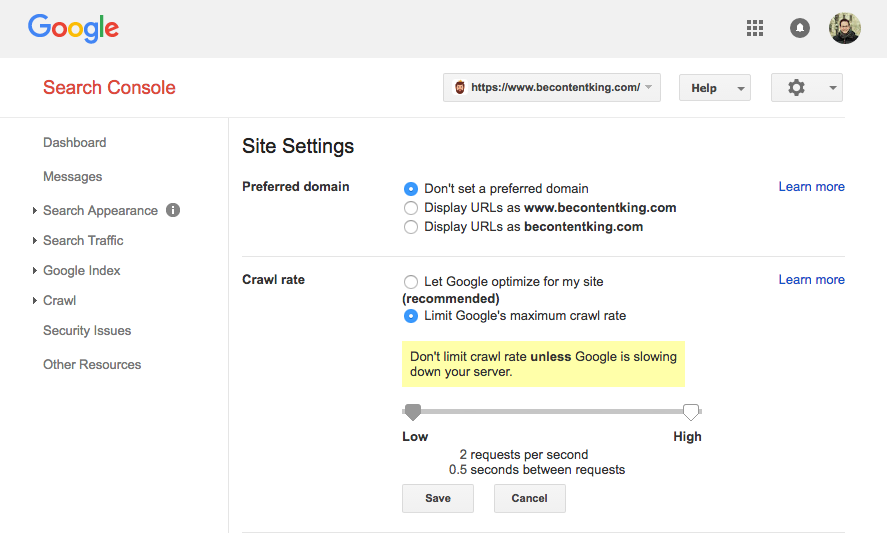
Google не падтрымлівае дырэктыву Crawl затрымкі. Тым не менш, Google не падтрымлівае вызначэнне хуткасці абыходу кантэнту ў Google Search Console. Выканайце наступныя дзеянні, каб ўсталяваць яго:
- Увайсці на Google Search Console.
- Абярыце вэб-сайт, які вы хочаце вызначыць хуткасць сканавання для.
- Націсніце на значок шасцярэнькі ў правым верхнім куце і абярыце «Настройкі сайта».
- Там ёсць опцыя называецца «Crawl хуткасць» з дапамогай паўзунка, дзе вы можаце ўсталяваць пераважны хуткасць сканавання. Па змаўчанні хуткасць сканавання усталёўваецца ў «Хай Google аптымізаваць для майго сайта (рэкамендуецца)».
Bing, Yahoo і Яндэкс
Bing, Yahoo і Яндэкс ўсе падтрымлівае дырэктыву Crawl затрымкі дросселировать сканаванне вэб-сайта. Іх інтэрпрэтацыя поўзання затрымкі адрозніваецца, хоць, так што не забудзьцеся праверыць іх дакументы:
Дырэктыва Crawl-затрымка павінна быць змешчана адразу пасля Disallow або Дазволіць дырэктывы.
прыклад:
Агент карыстальніка: BingBot Disallow: / прыватны / Crawl затрымкі: 10
Baidu
Baidu не падтрымлівае дырэктыву поўзаць затрымкі, аднак гэта магчыма зарэгістраваць акаўнт Інструментаў для вэб-майстроў з Baidu, у якім вы можаце кантраляваць частату сканавання, падобны на Google Search Console.
Калі выкарыстоўваць файл robots.txt?
Мы рэкамендуем заўсёды выкарыстоўваць файл robots.txt. Там няма абсалютна ніякай шкоды ў тым, каб адзін, і гэта выдатнае месца для пошуку ўручную рухавікоў дырэктыў аб тым, як найлепшым чынам яны могуць сканаваць ваш сайт.
Найлепшая практыка для файла robots.txt
Лепшыя метады для файлаў robots.txt класіфікуюцца наступным чынам:
Файл robots.txt павінен заўсёды знаходзіцца ў каранёвым каталогу вэб-сайта (у каталогу верхняга ўзроўню хаста) і несці імя файла robots.txt, напрыклад: https://www.example.com/robots.txt , Звярніце ўвагу, што URL для файла robots.txt, як і любы іншы URL, адчувальныя да рэгістра.
Калі файл robots.txt не можа быць знойдзены ў размяшчэнні па змаўчанні, пошукавыя сістэмы будуць лічыць, няма ніякіх указанняў і адпаўзці на сваім сайце.
парадак старшынства
Важна адзначыць, што пошукавыя сістэмы апрацоўваць файлы robots.txt па-рознаму. Па змаўчанні, першая дырэктыва адпаведнасці заўсёды перамагае.
Тым ня менш, з Google і Bing выйграе спецыфічнасць. Напрыклад: адрознівальная дырэктыва падкупляе дырэктыву Disallow, калі яго даўжыня сімвала больш.
прыклад
User-Agent: * Allow: / а / кампаніі / Disallow: / а /
У прыведзеным вышэй прыкладзе ўсіх пошукавых сістэм, у тым ліку Google і Bing не могуць атрымаць доступ да / о / каталогу, для паддырэкторыі / аб / кампаніі / акрамя.
прыклад
User-Agent: * Disallow: / аб / Allow: / а / кампаніі /
У прыведзеным вышэй прыкладзе ўсіх пошукавых сістэм Google і Bing , за выключэннем не мае доступ к / п / дырэкторыі, у тым ліку / аб / кампаніі /.
Google і Bing дазволены доступ , так як дырэктыва Allow больш , чым дырэктыва Disallow.
Толькі адна група дырэктыў на робата
Вы можаце вызначыць толькі адну групу дырэктыў у пошукавай сістэме. Наяўнасць некалькіх груп дырэктыў для адной пошукавай сістэмы блытае іх.
Будзьце як мага больш канкрэтным
Дырэктыва Disallow трыгеры на частковых супадзенняў, а таксама. Будзьце як мага больш канкрэтным пры вызначэнні дырэктывы Disallow для прадухілення ненаўмыснага забараняючы доступ да файлаў.
прыклад:
User-Agent: * Disallow: / Каталог
Прыведзены вышэй прыклад не дазваляе пошукавым машынам доступ да:
- / каталог
- / Каталог /
- / Каталог-імя-1
- /directory-name.html
- /directory-name.php
- /directory-name.pdf
Дырэктывы для ўсіх робатаў, а таксама уключаючы дырэктывы для канкрэтнага робата
Для робата толькі адна група дырэктыў з'яўляецца сапраўдным. У выпадку, калі дырэктывах прызначаныя для ўсіх робатаў вынікаюць дырэктывы для канкрэтнага робата, толькі гэтыя канкрэтныя дырэктывы будуць прынятыя да ўвагі. Для канкрэтнага робата таксама прытрымлівацца дырэктывам для ўсіх робатаў, вы павінны паўтарыць гэтыя дырэктывы для канкрэтнага робата.
Давайце паглядзім на прыклад, які зробіць гэта ясна:
прыклад
User-Agent: * Disallow: / Сакрэт / Disallow: / тэст / Disallow: / не запушчаны, пакуль / User-агент: GoogleBot Disallow: / не запушчаны, пакуль /
У прыведзеным вышэй прыкладзе ўсіх пошукавых сістэмах Google , за выключэннем не мае доступу / сакрэтным /, / тэст / і / не запушчаны, пакуль /. Google толькі не дазволены доступ да / не запушчаны, пакуль /, але дазволены доступ к / сакрэтным / і / тэст /.
Калі вы не хочаце Googlebot для доступу / сакрэце / і / не запушчаны, пакуль / то вам неабходна паўтарыць гэтыя дырэктывы для Googlebot а менавіта:
User-Agent: * Disallow: / Сакрэт / Disallow: / тэст / Disallow: / не запушчаны, пакуль / User-Agent: Googlebot Disallow: / Сакрэт / Disallow: / не запушчаны, пакуль /
Звярніце ўвагу, што файл robots.txt знаходзіцца ў адкрытым доступе. Забараняючы раздзелы сайта ў могуць быць выкарыстаны ў якасці вектара атакі людзей са злым намерам.
Файл robots.txt для кожнага (суб) дамена
Robots.txt дырэктывы прымяняюцца толькі да (суб) дамена файл, размешчаны на.
прыкладаў
http://example.com/robots.txt сапраўдная для http://example.com, але не для HTTP: // WWW .example.com або HTTP s: //example.com.
Гэта лепшая практыка толькі адзін файл robots.txt, даступны на вашым (суб) дамене, які скончыцца ў ContentKing мы аўдыт сайта для гэтага. Калі ў вас ёсць некалькі файлаў robots.txt даступныя, пераканайцеся, што альбо пераканацца, што яны вяртаюць статус HTTP 404, або 301-перанакіроўваць іх да кананічнага файл robots.txt.
Супярэчлівыя рэкамендацыі: robots.txt супраць Google Search Console
У выпадку, калі ваш файл robots.txt канфліктуе з параметрамі, вызначанымі ў Google Search Console, Google часта выбірае выкарыстоўваць параметры, вызначаныя ў Google Search Console над дырэктывамі, вызначанымі ў файле robots.txt.
Кантралюйце свой файл robots.txt
Вельмі важна, каб кантраляваць свой файл robots.txt для змен. У ContentKing, мы бачым шмат пытанняў, у якіх няправільныя дырэктывы і раптоўныя змены ў файл robots.txt выклікаць сур'ёзныя праблемы SEO. Гэта асабліва дакладна пры запуску новых функцый або новы вэб-сайт, які быў падрыхтаваны на тэставай асяроддзі, так як яны часта ўтрымліваюць наступны файл robots.txt:
User-Agent: * Disallow: /
мы пабудавалі robots.txt адсочвання змяненняў і абвесткі па гэтай прычыне.
Як вы ведаеце, калі ваш robots.txt змены?
Мы бачым гэта ўсё час: файлы robots.txt змены без ведама лічбавага маркетынгу. Не той чалавек. Пачаць маніторынг файл robots.txt Цяпер атрымліваць апавяшчэнні, калі ён змяняе!
Не выкарыстоўвайце NoIndex ў файле robots.txt
Хоць некаторыя кажуць, што гэта добрая ідэя, каб выкарыстоўваць NoIndex дырэктывы ў файле robots.txt, гэта не з'яўляецца афіцыйным стандарт і Google адкрыта рэкамендуе на ён не выкарыстоўваецца , Google не даў зразумець, чаму менавіта, але мы лічым, што мы павінны прыняць іх рэкамендацыі (у дадзеным выпадку) сур'ёзна. Гэта мае сэнс, таму што:
- Гэта цяжка адсочваць, якія старонкі павінны быць noindexed, калі вы выкарыстоўваеце некалькі спосабаў сігналізаваць ня індэксаваць старонкі.
- NOINDEX дырэктыва не дурань доказ, бо гэта не з'яўляецца афіцыйным стандартам. Выкажам здагадку, што не збіраецца прытрымлівацца на 100% Google.
- Мы ведаем толькі Google, выкарыстоўваючы NoIndex дырэктывы, іншыя пошукавыя сістэмы не будуць выкарыстоўваць яго для NoIndex старонак.
Лепшы спосаб сігналізаваць для пошукавых сістэм, што старонкі не павінны быць праіндэксаваныя ў выкарыстанні мета робатаў тэг або X-Robots-Tag , Калі вы не можаце выкарыстоўваць іх, і дырэктыва robots.txt NOINDEX ваш апошні курорт, чым вы можаце паспрабаваць, але мяркую, што гэта не будзе цалкам працаваць, то вы не будзеце расчараваныя.
Прыклады файла robots.txt
У гэтай частцы мы разгледзім шырокі спектр robots.txt прыкладаў файлаў.
Усе робаты могуць атрымаць доступ да ўсяго
Там у некалькі спосабаў паведаміць пошукавым сістэмам, яны могуць атрымаць доступ да ўсіх файлаў:
User-Agent: * Disallow:
Або маючы пусты файл robots.txt або не маюць robots.txt наогул.
Усе робаты не маюць доступу
User-Agent: * Disallow: /
Звярніце ўвагу: адзін дадатковы персанаж можа зрабіць усё адрозненне.
Усе боты Google не маюць доступу
User-Agent: Googlebot Disallow: /
Звярніце ўвагу, што, калі забараняючы Googlebot, гэта ставіцца да ўсіх Googlebots. Гэта ўключае ў сябе робат Google, якія шукаюць, напрыклад, для навін (Googlebot-News) і малюнкаў (Googlebot-малюнкі).
Усе боты Google, навіны Googlebot акрамя не маюць доступу
User-Agent: Googlebot Disallow: / User-Agent: Googlebot-навіны Disallow:
Googlebot і Slurp не маюць доступу
Агент карыстальніка: Slurp User-Agent: Googlebot Disallow: /
Усе робаты не маюць доступу да двух каталогах
User-Agent: * Disallow: / адміністратар / Disallow: / прыватных /
Усе робаты не маюць доступу да аднаго канкрэтнаму файлу
User-Agent: * Disallow: /directory/some-pdf.pdf
Googlebot не мае доступу да / адмін / і Slurp не мае доступу да / прыватных /
User-Agent: Googlebot Disallow: / адміністратар / User-агент: Slurp Disallow: / прыватны /
Robots.txt для WordPress
Файл robots.txt ніжэй спецыяльна аптымізаваны для WordPress, мяркуючы, што:
- Вы не хочаце, каб ваш адмін падзел для сканавання.
- Вы не хочаце, каб вашы ўнутранага пошук старонак вынікаў сканавання.
- Вы не хочаце, каб вашы тэгі і аўтар старонкі скануецца.
- Вы не хочаце, каб ваша старонка 404 для сканавання.
User-Agent: * Disallow: / WP-адміністратар / #block доступ да адмін секцыі Disallow: /wp-login.php доступ #block да адмін секцыі Disallow: / пошук / доступ #block на ўнутраныя старонкі вынікаў пошуку Disallow: * s = * #block доступ да унутраным старонках вынікаў пошуку Disallow: * р = * #block доступ да старонак, для якіх не ўдаецца Permalinks Disallow: * & р = * #block доступ да старонак, для якіх не ўдаецца Permalinks Disallow: * & прагляд = * доступ #block для прагляду старонак Disallow: / тэгі / #block доступу да старонак тэгаў Disallow: / аўтар / #block доступ да старонак аўтара Disallow: 404 памылак / доступ / #block на 404 старонцы сайта: https://www.example.com/ sitemap_index.xml
Звярніце ўвагу , што гэты файл robots.txt будзе працаваць у большасці выпадкаў, але вы заўсёды павінны наладзіць яго і пратэставаць яго , каб пераканацца , што ён ставіцца да вашай канкрэтнай сітуацыі.
Якія абмежаванні robots.txt?
Файл robots.txt ўтрымлівае дырэктывы
Нягледзячы на тое, robots.txt добра паважалі пошукавыя сістэмы, гэта яшчэ дырэктыва, а не мандат.
Старонкі працягваюць з'яўляцца ў выніках пошуку
Старонкі, якія недаступныя для пошукавых сістэм з-за robots.txt, але ёсць спасылкі на іх можа па-ранейшаму з'яўляцца ў выніках пошуку, калі яны звязаны са старонкі, які поўз. Прыклад таго, што гэта выглядае наступным чынам:

Protip: гэта магчыма , каб выдаліць гэтыя адрасы з Google з дапамогай прылады выдалення URL Google Search кансолі. Звярніце ўвагу, што гэтыя адрасы будуць часова выдаленыя толькі. Для таго, каб ім застацца па-за старонкі вынікаў Google, вам трэба выдаліць URL, кожныя 90 дзён.
кэшаванне
Google паказаў, што файл robots.txt, як правіла, кэшуюцца да 24 гадзін. Важна, каб прыняць гэта да ўвагі, калі вы робіце змены ў файле robots.txt.
Пакуль незразумела, як іншыя пошукавыя сістэмы маюць справу з кэшаваннем robots.txt, але ў цэлым лепш пазбягаць кэшавання вашага файла robots.txt, каб пазбегнуць пошукавых сістэм займае больш часу, чым гэта неабходна, каб мець магчымасць падняць на змены.
памер файла
Для файлаў robots.txt Google у цяперашні час падтрымлівае абмежаванне на памер файла 500 кб. Любое ўтрыманне пасля гэтага максімальнага памеру файла можа быць праігнаравана.
Пакуль незразумела, ці можа іншыя пошукавыя сістэмы маюць максімальны памер файл для файлаў robots.txt.
Часта задаюць пытанні аб robots.txt
- Ці будзе з дапамогай файлаў robots.txt, каб пошукавыя сістэмы, паказваючы забароненыя старонкі ў старонках вынікаў пошукавай сістэмы?
- Ці павінен я быць асцярожным з дапамогай файлаў robots.txt?
- Ці з'яўляецца гэта незаконным ігнараваць robots.txt, калі выскрабанне вэб-сайт?
- У мяне няма файла robots.txt. Ці будуць пошукавыя сістэмы па-ранейшаму сканаваць мой сайт?
- Ці магу я выкарыстаць NoIndex замест Disallow ў файле robots.txt?
- Якія пошукавыя сістэмы паважаюць файл robots.txt?
- Як я магу прадухіліць пошукавыя сістэмы з вынікаў пошуку індэксацыі старонак на маім сайце WordPress?
1. Ці будзе з дапамогай файлаў robots.txt, каб пошукавыя сістэмы, паказваючы забароненыя старонкі ў старонках вынікаў пошукавай сістэмы?
Не, вазьміце гэты прыклад:
Акрамя таго : калі старонка забароненая з дапамогай robots.txt і сама старонка ўтрымлівае <META NAME = «Robots» Content = «NoIndex, NOFOLLOW»> то пошукавыя сістэмы робатаў ўсё яшчэ будуць трымаць старонку ў індэксе, таму што яны ніколі не будуць даведацца аб <META NAME = «робаты» змест = «NOINDEX, NOFOLLOW»>, так як яны не маюць права доступу.
2. Ці павінен я быць асцярожным з дапамогай файлаў robots.txt?
Так, вы павінны быць асцярожныя. Але не бойцеся выкарыстоўваць яго. Гэта выдатны інструмент, каб дапамагчы пошукавым сістэмам лепш сканаваць ваш сайт.
3. Ці з'яўляецца гэта незаконным ігнараваць robots.txt, калі выскрабанне вэб-сайт?
З тэхнічнага пункту гледжання, няма. Файл robots.txt з'яўляецца неабавязковай дырэктывай. Мы нічога не можам сказаць, калі з юрыдычнага пункту гледжання.
4. У мяне няма файла robots.txt. Ці будуць пошукавыя сістэмы па-ранейшаму сканаваць мой сайт?
Так. Калі пошукавік не сутыкаецца файл robots.txt ў каранёвай каталогу (у каталогу верхняга ўзроўню хаста), яны будуць лічыць, няма ніякіх указанняў для іх, і яны будуць спрабаваць сканаваць ўвесь сайт.
5. Ці магу я выкарыстаць NoIndex замест Disallow ў файле robots.txt?
Не, гэта не рэкамендуецца. Google у прыватнасці, рэкамендуе супраць выкарыстання NoIndex дырэктывы ў файле robots.txt.
6. Якія пошукавыя сістэмы паважаюць файл robots.txt?
Мы ведаем, што ўсе асноўныя пошукавыя сістэмы ніжэй дачыненні robots.txt файла:
7. Як я магу прадухіліць пошукавыя сістэмы з вынікаў пошуку індэксацыі старонак на маім сайце WordPress?
У тым ліку наступныя дырэктывы ў файле robots.txt перашкаджае ўсім пошукавым сістэмам індэксаванне старонкі вынікаў пошуку на вашым сайце WordPress, ня прадугледжваюць ніякіх зменаў былі зробленыя для функцыянавання на старонках вынікаў пошуку.
User-Agent: * Disallow: / s = Disallow: / пошук /
далейшае чытанне
Txt?Txt працуе супраць вас?
Txt?
Txt змены?
Txt?
Txt?
Txt, калі выскрабанне вэб-сайт?
Ці будуць пошукавыя сістэмы па-ранейшаму сканаваць мой сайт?
Txt?
Txt?