
Jednym z dostępnych algorytmów łączenia dwóch tabel w SQL Server są zagnieżdżone pętle (zagnieżdżone pętle). W zależności od kolejności łączenia tabel wybranej przez optymalizator, jedna z tabel jest wybierana jako zewnętrzna (otwiera zewnętrzną pętlę), druga jako wewnętrzna (dla każdego wiersza z tabeli zewnętrznej, pętla wewnętrzna jest wykonywana na drugiej tabeli), podczas łączenia warunek łączenia jest sprawdzany wewnątrz pętli takie podejście nazywane jest „naiwnym” algorytmem zagnieżdżonej pętli. Jeśli indeks w warunku łączenia jest dostępny w tabeli wewnętrznej, nie jest konieczne wykonywanie wewnętrznej pętli kontrolnej w każdym wierszu drugiej tabeli, zamiast tego można przekazać wartość z tabeli zewnętrznej jako argument wyszukiwania i połączyć wszystkie wiersze znajdujące się w tabeli wewnętrznej z wierszem z tabeli zewnętrznej.
Przeszukiwanie wewnętrznej tabeli jest przypadkowe, SQL Server od wersji 2005 ma optymalizację nazywaną sortowaniem wsadowym (nie należy mylić z operatorem sortowania w trybie wsadowym dla indeksów kolumn). Optymalizacja polega na tym, aby przed pobraniem danych z wewnętrznej tabeli zorganizować klucze wyszukiwania z zewnętrznego, zmieniając tym samym losowy dostęp w sekwencyjny dostęp.
Operacja sortowania wsadowego nie jest widoczna w planie kwerend jako oddzielna instrukcja, zamiast tego można zobaczyć właściwość Zoptymalizowana = w instrukcji Zagnieżdżone pętle. Gdybyś mógł zobaczyć sortowanie wsadowe jako osobną instrukcję w planie, wyglądałoby to mniej więcej tak: 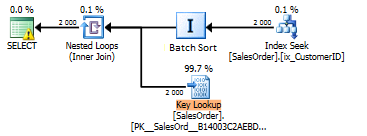
W tym „pseudo-planie” odczytujemy dane z nieklastrowanego indeksu ix_CustomerID w kolejności klucza tego indeksu CustomerID, po czym musimy wykonać wyszukiwanie klucza w indeksie klastra (ponieważ indeks ix_CustomerID nie obejmuje zapytania, dla którego to „Pseudo-plan”). Wyszukiwanie klucza jest operacją wyszukiwania klucza indeksu klastra, dostęp losowy i przekształcenie go w serwer sekwencyjny może sortować wsadowo na klucz indeksu klastra.
Możesz przeczytać więcej o sortowaniu wsadowym w moim anglojęzycznym blogu w artykule Sortowanie wsadowe i pętle zagnieżdżone .
Ta optymalizacja daje dobre przyspieszenie z wystarczającą liczbą linii, można zobaczyć wyniki testowania wpływu tej optymalizacji na blogu jednego z twórców optymalizatora Craiga Friedmana. OPTYMALIZACJA Zagnieżdżonych pętli .
Jeśli jednak linie są mniejsze niż oczekiwano, dodatkowe koszty procesora związane z budowaniem tego sortowania mogą ukryć jego zalety, zwiększyć zużycie procesora i spowolnić wykonywanie. Zanim pojawiła się wskazówka DISABLE_OPTIMIZED_NESTED_LOOP, Microsoft zasugerował w tym przypadku użycie flagi śledzenia 2340, wyłącza tę optymalizację. Teraz nie jest to konieczne i możemy użyć wskazówki DISABLE_OPTIMIZED_NESTED_LOOP.
Przykład
Rozważmy przykład:
użyj tempdb; przejdź - Utwórz tabelę testową (SalesOrderID - klastrowany PC) utwórz tabelę dbo.SalesOrder (SalesOrderID int klucz podstawowy, CustomerID int nie null, SomeData char (200) nie null); go - Wypełnij go danymi testowymi za pomocą n as (wybierz top (1000000) rn = numer_wiersza () ponad (kolejność według (wybierz wartość null)) z sys.all_columns c1, sys.all_columns c2) wstaw dbo.SalesOrder (CustomerID, SomeData) wybierz rn% 500000, str (rn, 100) z n; - Utwórz indeks nieklastrowany, utwórz indeks ix_c na dbo.Salesorder (CustomerID); go - domyślnie włączona jest optymalizacja sortowania wsadowego (Nested Loops: Optimized = true) wybierz * z dbo.SalesOrder z (index (ix_c)) gdzie CustomerID <1000; - Wyłącz ją za pomocą wskazówki DISABLE_OPTIMIZED_NESTED_LOOP (Zagnieżdżone pętle: Optimized = false) wybierz * z dbo.SalesOrder z (index (ix_c)) gdzie CustomerID <1000 opcja (użyj podpowiedzi ('DISABLE_OPTIMIZED_NESTED_LOOP')); idź
Wynik: 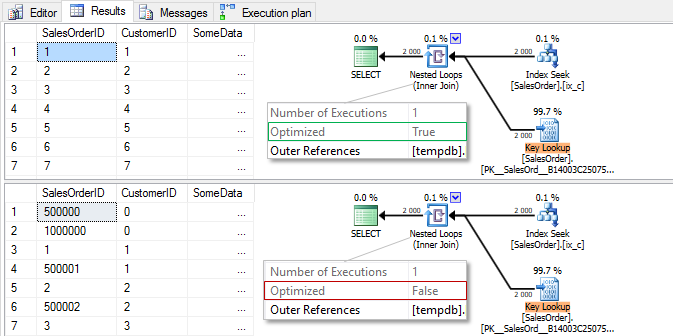
Zwróć uwagę na inną kolejność linii na wyjściu, ponieważ nie mamy wyraźnej kolejności określonej za pomocą ORDER BY, serwer zwraca wiersze w kolejności ich przetwarzania. W pierwszym przypadku konsekwentnie czytamy z indeksu ix_c, ale w celu optymalizacji losowych odczytów z indeksu klastrowego sortujemy według klucza indeksu klastra SalesOrderID. W drugim przypadku sortowanie nie występuje, a odczyty są w kolejności kluczy CustomerID w indeksie nieklastrowanym ix_c.
Różnica z flagą 2340
Mimo to dokumentacja Flaga 2340 jest określona jako odpowiednik wskazówki DISABLE_OPTIMIZED_NESTED_LOOP, ale tak nie jest. 
Rozważmy następujący przykład, w którym za pomocą nieudokumentowanego polecenia UPDATE STATISTICS ... WITH PAGECOUNT oszukam optymalizatora, mówiąc, że tabela zajmuje więcej stron niż jest w rzeczywistości. Używanie tego polecenia nie jest ważne, można było po prostu rozszerzyć tabelę, ale chcę zaoszczędzić czas. Następnie przyjrzymy się trzem żądaniom:
- bez żadnych podpowiedzi (MAXDOP, dodano, aby zapisać prostą formę planu);
- z podpowiedzią DISABLE_OPTIMIZED_NESTED_LOOP;
- z flagą śledzenia 2340.
- Symuluj szerokie statystyki aktualizacji tabeli dbo.SalesOrder z liczbą stron = 100000; idź ustaw showplan_xml na; go - 1. Bez podpowiedzi wybierz * z dbo.SalesOrder z (index (ix_c)) gdzie CustomerID <1000000 opcja (maxdop 1); - 2. Podpowiedź wybierz * z dbo.SalesOrder z (index (ix_c)) gdzie CustomerID <opcja 1000000 (użyj podpowiedzi ('DISABLE_OPTIMIZED_NESTED_LOOP'), maxdop 1); - 3. Flaga Trace wybierz * z dbo.SalesOrder z (index (ix_c)) gdzie CustomerID <opcja 1000000 (querytraceon 2340, maxdop 1); idź wyłącz showplan_xml; idź
W rezultacie otrzymamy następujące plany:
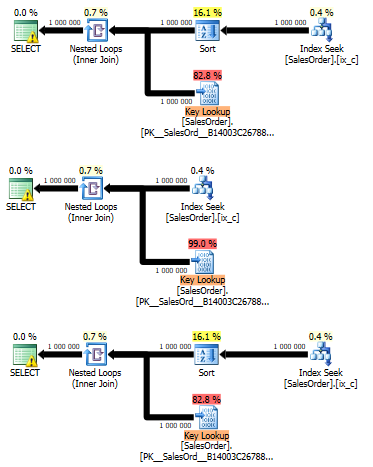
We wszystkich trzech planach Nested Loops ma właściwość Optimized = false. Faktem jest, że zwiększając szerokość tabeli, zwiększyliśmy koszt dostępu do danych. Przy wystarczająco wysokim koszcie serwer może zdecydować, zamiast domyślnego sortowania wsadowego, użyć jawnego operatora sortowania Sort, co w tym przypadku robi. Widzimy to pod względem pierwszej prośby.
W drugim zapytaniu użyliśmy wskazówki DISABLE_OPTIMIZED_NESTED_LOOP, która wyłącza niejawną partię sortowania, ale usuwa także jawne sortowanie przez oddzielnego operatora. W trzecim planie widzimy, że pomimo dodania flagi 2340, obecny jest operator sortowania.
Zatem wskazówka różni się od flagi tym, że wyłącza optymalizację konwersji losowego dostępu do sekwencyjnego całkowicie, niezależnie od tego, jak serwer zdecyduje się go zaimplementować, używając niejawnego sortowania sortowania wsadowego lub używając oddzielnego operatora sortowania.
W następny Uwaga: porozmawiamy o wskazówkach FORCE_LEGACY_CARDINALITY_ESTIMATION i FORCE_DEFAULT_CARDINALITY_ESTIMATION.
PS Plany w tej notatce mogą zależeć od sprzętu, więc jeśli nie możesz odtworzyć przykładów, spróbuj zwiększyć lub zmniejszyć rozmiar kolumny char (200) SomeData w definicji tabeli dbo.SalesOrder.