
- Коротко кажучи, Robots.txt Файл robots.txt містить директиви для пошукових систем, які можна використовувати...
- Термінологія навколо файлу robots.txt
- Чому ви повинні дбати про файл robots.txt?
- Приклад
- Ваш robots.txt працює проти вас?
- User-agent у файлі robots.txt
- Заборонити в robots.txt
- Приклад
- Дозволити в файлі robots.txt
- Приклад
- Приклад конфліктуючих директив
- Окрему рядок для кожної директиви
- Використання шаблону *
- Приклад
- Використання кінця URL $
- Приклад
- Мапа сайту в файлі robots.txt
- Приклади
- Приклад 1
- Приклад 2
- Затримка сканування у файлі robots.txt
- Приклад:
- Коли використовувати файл robots.txt?
- Кращі методи для файлу robots.txt
- Порядок пріоритету
- Приклад
- Приклад
- Тільки одна група директив на робота
- Будьте максимально конкретними
- Приклад:
- Директиви для всіх роботів, а також директиви для конкретного робота
- Приклад
- Файл Robots.txt для кожного (під) домену
- Приклади
- Конфліктні рекомендації: robots.txt проти консолі пошуку Google
- Відстежуйте файл robots.txt
- Як дізнатися, коли змінюється файл robots.txt?
- Не використовуйте noindex у файлі robots.txt
- Приклади файлів robots.txt
- Всі роботи можуть отримати доступ до всього
- Всі роботи не мають доступу
- Усі боти Google не мають доступу
- Всі боти Google, окрім новин Googlebot, не мають доступу
- Googlebot і Slurp не мають доступу
- Всі роботи не мають доступу до двох каталогів
- Всі роботи не мають доступу до одного конкретного файлу
- Googlebot не має доступу до / admin / і Slurp не має доступу до / private /
- Robots.txt для WordPress
- Які обмеження файлу robots.txt?
- Сторінки все ще відображаються в результатах пошуку
- Кешування
- Розмір файлу
- Часті запитання про файл robots.txt
- 1. Чи запобігає використання файлу robots.txt, щоб пошукові системи не показували заборонені сторінки...
- 2. Чи слід обережно використовувати файл robots.txt?
- 3. Чи є незаконним ігнорувати файл robots.txt під час вибору веб-сайту?
- 4. У мене немає файлу robots.txt. Чи будуть пошукові системи ще сканувати мій веб-сайт?
- 5. Чи можу я використовувати файл Noindex замість Disallow у файлі robots.txt?
- 6. Які пошукові системи поважають файл robots.txt?
- 7. Як запобігти індексації пошуковими системами сторінок результатів пошуку на моєму веб-сайті WordPress?
Коротко кажучи, Robots.txt
Файл robots.txt містить директиви для пошукових систем, які можна використовувати для запобігання скануванням пошуковими системами окремих частин вашого веб-сайту.
При впровадженні файлу robots.txt слід мати на увазі такі найкращі практики:
- Будьте уважні при внесенні змін до вашого файлу robots.txt: цей файл має потенціал зробити великі частини вашого сайту недоступними для пошукових систем.
- Файл robots.txt повинен знаходитися в корені вашого веб-сайту (наприклад, http://www.example.com/robots.txt).
- Файл robots.txt дійсний лише для повного домену, на якому він знаходиться, включаючи протокол (http або https).
- Різні пошукові системи по-різному інтерпретують директиви. За замовчуванням перша відповідна директива завжди виграє. Але, з Google і Bing, специфічність виграє.
- Уникайте використання директиви про скасування затримки для пошукових систем, наскільки це можливо.
Що таке файл robots.txt?
Файл robots.txt повідомляє пошуковим системам правила взаємодії вашого веб-сайту.
Пошукові системи регулярно перевіряють файл robots.txt веб-сайту, щоб дізнатися, чи є інструкції щодо сканування веб-сайту. Ми називаємо ці інструкції 'директивами'.
Якщо файл robots.txt не присутній або немає відповідних директив, пошукові системи будуть сканувати весь веб-сайт.
Хоча всі основні пошукові системи поважають файл robots.txt, пошукові системи можуть ігнорувати (частини) вашого файлу robots.txt. Хоча директиви в файлі robots.txt є сильним сигналом для пошукових систем, важливо пам'ятати, що файл robots.txt - це набір додаткових директив для пошукових систем, а не мандат.
Термінологія навколо файлу robots.txt
Файл robots.txt є реалізацією стандарту виключення роботів або також називається протоколом виключення роботів .
Чому ви повинні дбати про файл robots.txt?
Файл robots.txt відіграє важливу роль з точки зору пошукової оптимізації (SEO). Він повідомляє пошуковим системам, як вони можуть краще сканувати ваш сайт.
Використовуючи файл robots.txt, ви можете запобігти доступу пошукових систем до певних частин вашого веб-сайту , запобігати дублюванню вмісту та надавати пошуковим машинам корисні поради щодо ефективнішого сканування вашого веб-сайту.
Будьте обережні при внесенні змін до файлу robots.txt: цей файл має потенціал зробити великі частини вашого сайту недоступними для пошукових систем.
Приклад
Давайте розглянемо приклад, щоб проілюструвати це:
Ви запускаєте веб-сайт електронної комерції, і відвідувачі можуть використовувати фільтр для швидкого пошуку ваших продуктів. Цей фільтр створює сторінки, які в основному показують той самий вміст, що й інші сторінки. Це відмінно працює для користувачів, але заплутує пошукові системи, оскільки вони створюються дубльований вміст . Ви не хочете, щоб пошукові системи індексували ці відфільтровані сторінки та витрачали їх на ці URL-адреси з відфільтрованим вмістом. Для цього потрібно встановити правила Заборонити, щоб пошукові системи не мали доступу до цих фільтрованих сторінок продукту.
Запобігання дублювання вмісту також можна здійснювати за допомогою канонічний URL або тег мета-роботів, однак вони не стосуються, дозволяючи пошуковим системам тільки сканувати важливі сторінки. Використання канонічної URL-адреси або тега мета-роботів не перешкоджатиме скануванню цих сторінок пошуковими системами. Це лише заважатиме пошуковим системам відображати ці сторінки в результатах пошуку . З пошуковими системами є обмежити час для сканування веб-сайту , цей час треба витратити на сторінки, які ви хочете з'явитися в пошукових системах.
Ваш robots.txt працює проти вас?
Неправильно налаштований файл robots.txt може стримувати ефективність вашого SEO. Переконайтеся, що це саме так для Вашого веб-сайту!
Приклад того, як може виглядати простий файл robots.txt для веб-сайту WordPress:
User-agent: * Disallow: / wp-admin /
Розглянемо анатомію файлу robots.txt на основі наведеного вище прикладу:
- User-agent: користувальницький агент вказує, для яких пошукових систем маються на увазі наступні директиви.
- *: це означає, що директиви призначені для всіх пошукових систем.
- Заборонити: це директива, яка вказує, який вміст недоступний користувальницькому агенту.
- / wp-admin /: це шлях, який недоступний для користувача-агента.
У підсумку: цей файл robots.txt повідомляє всім пошуковим системам, що залишаються поза каталогом / wp-admin /.
User-agent у файлі robots.txt
Кожна пошукова система повинна ідентифікувати себе з користувальницьким агентом. Роботи Google ідентифікують Googlebot, наприклад, роботів Yahoo як робота Slurp і Bing як BingBot і так далі.
Запис користувача-агента визначає початок групи директив. Всі директиви між першим користувальницьким агентом і наступним записом користувача-агента розглядаються як директиви для першого користувача-агента.
Директиви можуть застосовуватися до певних користувальницьких агентів, але вони також можуть бути застосовні до всіх користувачів-агентів. У цьому випадку використовується шаблон: User-agent: *.
Заборонити в robots.txt
Ви можете вказати пошуковим системам не доступ до певних файлів, сторінок або розділів вашого веб-сайту. Це робиться за допомогою директиви Disallow. За директивою Disallow йде шлях, до якого не слід звертатися. Якщо не визначено жодного шляху, директива ігнорується.
Приклад
User-agent: * Disallow: / wp-admin /
У цьому прикладі всім пошуковим системам сказано, що вони не мають доступу до каталогу / wp-admin /.
Дозволити в файлі robots.txt
Директива Allow використовується для протидії директиві Disallow. Директиву Allow підтримують Google і Bing. Використовуючи разом директиви Allow і Disallow, ви можете сказати пошуковим системам, що вони можуть отримати доступ до певного файлу або сторінки в каталозі, який інакше заборонено. За директивою Allow слід шлях, до якого можна отримати доступ. Якщо не визначено жодного шляху, директива ігнорується.
Приклад
User-agent: * Дозволити: /media/terms-and-conditions.pdf Заборонити: / media /
У наведеному вище прикладі всі пошукові системи не мають доступу до каталогу / media /, за винятком файлу /media/terms-and-conditions.pdf.
Важливо: при використанні директив Allow і Disallow разом, переконайтеся, що не використовуються символи, оскільки це може призвести до конфліктуючих директив.
Приклад конфліктуючих директив
User-agent: * Дозволити: / каталог Disallow: /*.html
Пошукові системи не знатимуть, що робити з URL-адресою http://www.domain.com/directory.html. Їм незрозуміло, чи дозволено доступ.
Окрему рядок для кожної директиви
Кожна директива повинна бути в окремому рядку, інакше пошукові системи можуть заплутатися при аналізі файлу robots.txt.
Приклад неправильного файлу robots.txt
Запобігання файлу robots.txt таким чином:
Користувальницький агент: * Disallow: / directory-1 / Disallow: / directory-2 / Disallow: / directory-3 /
Використання шаблону *
Для визначення користувача-агента може використовуватися не тільки шаблон, він також може використовуватися для узгодження URL-адрес. Шаблон підтримується Google, Bing, Yahoo і Ask.
Приклад
User-agent: * Disallow: / *?
У наведеному вище прикладі всі пошукові системи не мають доступу до URL-адрес, які містять знак запитання (?).
Використання кінця URL $
Щоб вказати кінець URL-адреси, можна скористатися знаком долара ($) в кінці шляху.
Приклад
User-agent: * Disallow: /*.php$
У наведеному вище прикладі пошукові системи не мають доступу до всіх URL-адрес, які закінчуються на .php. URL-адреси з параметрами, наприклад, https://example.com/page.php?lang=en, не буде заборонено, оскільки URL-адреса не закінчується після .php.
Мапа сайту в файлі robots.txt
Незважаючи на те, що файл robots.txt був винайдений, щоб повідомити пошуковим системам, які сторінки не сканувати , файл robots.txt також може бути використаний для пошуку пошукових систем до XML-карти сайту. Це підтримується Google, Bing, Yahoo і Ask.
XML-карту сайту слід посилатися як на абсолютну URL-адресу. URL-адреса не повинна бути на тому ж хості, що й файл robots.txt. Посилання на файл Sitemap XML у файлі robots.txt є однією з найкращих практик, яку ми завжди радимо робити, навіть якщо ви вже надіслали XML-карту сайту в консолі пошуку Google або Bing Webmaster Tools. Пам'ятайте, що там більше пошукових систем.
Зауважте, що можна скористатися кількома файлами XML у файлі robots.txt.
Приклади
Кілька Sitemap XML:
Агент користувача: * Disallow: / wp-admin / Sitemap: https://www.example.com/sitemap1.xml Карта сайту: https://www.example.com/sitemap2.xml
У наведеному вище прикладі всім пошуковим системам не слід звертатися до каталогу / wp-admin / і що існують два XML-мапи сайту, які можна знайти за адресою https://www.example.com/sitemap1.xml і https: //www.example .com / sitemap2.xml.
Один Sitemap XML:
Агент користувача: * Disallow: / wp-admin / Sitemap: https://www.example.com/sitemap_index.xml
У наведеному вище прикладі всі пошукові системи не мають доступу до каталогу / wp-admin / і що XML-карту можна знайти на веб-сторінці https://www.example.com/sitemap_index.xml.
Коментарі передують символу # і можуть бути розміщені на початку рядка або після директиви на тій же лінії. Все після # буде проігноровано. Ці коментарі призначені тільки для людей.
Приклад 1
# Не дозволяйте доступ до каталогу / wp-admin / для всіх роботів. User-agent: * Disallow: / wp-admin /
Приклад 2
User-agent: * # Застосовується до всіх роботів Disallow: / wp-admin / # Не дозволяйте доступ до каталогу / wp-admin /.
Наведені вище приклади повідомляють однаково.
Затримка сканування у файлі robots.txt
Інструкція Crawl-delay є неофіційною директивою, що використовується для запобігання перевантаження серверів із занадто великою кількістю запитів. Якщо пошукові системи здатні перевантажити сервер, додавання затримки сканування до файлу robots.txt - це лише тимчасове виправлення. Справа в тому, ваш веб-сайт працює на поганому хостинг середовищі, і ви повинні виправити це якомога швидше.
Те, як пошукові системи обробляють затримку сканування, відрізняється. Нижче ми пояснюємо, як це виконують основні пошукові системи.
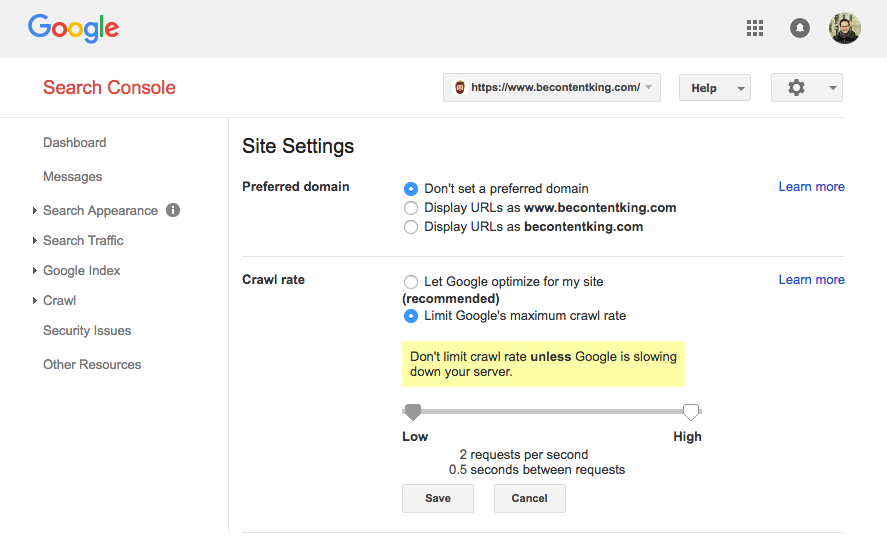
Google не підтримує директиву Crawl-delay. Однак Google підтримує визначення швидкості сканування в консолі пошуку Google. Щоб встановити його, виконайте наведені нижче дії.
- Увійдіть до консолі пошуку Google.
- Виберіть веб-сайт, для якого потрібно визначити швидкість сканування.
- Натисніть на значок шестерні вгорі праворуч і виберіть "Налаштування сайту".
- Існує опція "Швидкість сканування" з повзунком, де можна встановити бажану швидкість сканування. За умовчанням швидкість сканування встановлюється як "Дозволити Google оптимізувати мій сайт (рекомендовано)".
Bing, Yahoo і Яндекс
Bing, Yahoo і Yandex всі підтримують директиву Crawl-delay для придушення сканування веб-сайту. Однак їх інтерпретація затримки сканування відрізняється, тому обов'язково перевірте їх документацію:
Інструкція Crawl-delay повинна бути розміщена відразу після директив Disallow або Allow.
Приклад:
User-agent: BingBot Disallow: / private / Crawl-delay: 10
Baidu
Baidu не підтримує директиву про затримку сканування, однак можна зареєструвати обліковий запис інструментів для веб-майстрів Baidu, за допомогою якого можна контролювати частоту сканування, подібну до консолі пошуку Google.
Коли використовувати файл robots.txt?
Ми рекомендуємо завжди використовувати файл robots.txt. Там абсолютно ніякої шкоди в тому, що один, і це відмінне місце для рук пошукових директив про те, як вони можуть краще сканування вашого сайту.
Кращі методи для файлу robots.txt
Найкращі практики для файлів robots.txt поділяються на такі категорії:
Файл robots.txt завжди повинен бути розміщений у корені веб-сайту (у каталозі верхнього рівня хоста) та мати назву файла robots.txt, наприклад: https://www.example.com/robots.txt . Зауважте, що URL-адреса файлу robots.txt, як і будь-яка інша URL-адреса, залежить від регістру.
Якщо файл robots.txt не може бути знайдений у розташуванні за умовчанням, пошукові системи припускатимуть, що немає директив і сканування на вашому веб-сайті.
Порядок пріоритету
Важливо відзначити, що пошукові системи по-різному обробляють файли robots.txt. За замовчуванням перша відповідна директива завжди виграє .
Проте з Google і Bing виграє специфічність . Наприклад: директива Allow виграє над директивою Disallow, якщо її довжина символу довша.
Приклад
User-agent: * Дозволити: / про компанію / Disallow: / about /
У наведеному вище прикладі всі пошукові системи, включаючи Google і Bing, не мають доступу до каталогу / about /, крім підкаталогу / about / company /.
Приклад
User-agent: * Disallow: / about / Allow: / про компанію /
У наведеному вище прикладі всі пошукові системи, крім Google і Bing , не мають доступу до / about / directory, включаючи / about / company /.
Google і Bing мають дозвіл на доступ, оскільки директива Allow є більшою, ніж директива Disallow.
Тільки одна група директив на робота
Ви можете визначити лише одну групу директив на пошукову систему. Наявність декількох груп директив для однієї пошукової системи заплутує їх.
Будьте максимально конкретними
Директива забороняє також і на часткові збіги. Будьте максимально конкретними при визначенні директиви Disallow, щоб запобігти ненавмисному забороні доступу до файлів.
Приклад:
User-agent: * Disallow: / каталог
Наведений вище приклад не дозволяє доступу до пошукових систем до:
- / каталог
- / каталог /
- / directory-name-1
- /directory-name.html
- /directory-name.php
- /directory-name.pdf
Директиви для всіх роботів, а також директиви для конкретного робота
Для робота діє лише одна група директив. У випадку, якщо директиви, призначені для всіх роботів, дотримуються директив для конкретного робота, тільки ці специфічні директиви будуть розглянуті. Для того, щоб конкретний робот також дотримувався директив для всіх роботів, потрібно повторити ці директиви для конкретного робота.
Давайте подивимося на приклад, який зробить це ясно:
Приклад
Агент користувача: * Disallow: / secret / Disallow: / test / Disallow: / not-started-yet / User-agent: googlebot Disallow: / not-started-yet /
У наведеному вище прикладі всі пошукові системи, крім Google , не мають права доступу / secret /, / test / і / not-started-yet /. Google не має доступу до / not-started-yet /, але має доступ до / secret / and / test /.
Якщо ви не хочете, щоб Googlebot мав доступ / secret / and / not-started-yet / тоді вам потрібно повторити ці директиви для Googlebot конкретно:
User-agent: * Disallow: / secret / Disallow: / test / Disallow: / not-started-yet / Користувач-агент: googlebot Disallow: / secret / Disallow: / not-started-yet /
Зауважте, що файл robots.txt є загальнодоступним. Забороняючи розділи веб-сайту, вони можуть бути використані як вектор атаки для людей з шкідливими намірами.
Файл Robots.txt для кожного (під) домену
Директиви Robots.txt застосовуються тільки до (під) домену, на якому розміщений файл.
Приклади
http://example.com/robots.txt дійсний для http://example.com, але не для http: // www .example.com або http s : //example.com.
Найкращою практикою є лише наявність одного файлу robots.txt у вашому (під) домені, що знаходиться в ContentKing, ми перевіряємо ваш веб-сайт для цього. Якщо у вас є декілька доступних файлів robots.txt, переконайтеся, що вони повертають статус 404 HTTP, або 301-перенаправляйте їх до канонічного файлу robots.txt.
Конфліктні рекомендації: robots.txt проти консолі пошуку Google
Якщо ваш файл robots.txt суперечить параметрам, визначеним у консолі пошуку Google, Google часто вибирає параметри, визначені в консолі пошуку Google, над директивами, визначеними у файлі robots.txt.
Відстежуйте файл robots.txt
Важливо стежити за змінами у файлі robots.txt. У ContentKing ми бачимо багато проблем, де неправильні директиви та раптові зміни файлу robots.txt викликають серйозні проблеми SEO. Це особливо стосується запуску нових функцій або нового веб-сайту, підготовленого в тестовому середовищі, оскільки вони часто містять такий файл robots.txt:
User-agent: * Disallow: /
Ми побудували відстеження та оповіщення про зміну robots.txt з цієї причини.
Як дізнатися, коли змінюється файл robots.txt?
Ми бачимо це весь час: файли robots.txt змінюються без знання команди цифрового маркетингу. Не будьте такою людиною. Почніть моніторинг файлу robots.txt, тепер отримуйте сповіщення, коли він змінюється!
Не використовуйте noindex у файлі robots.txt
Хоча деякі кажуть, що це гарна ідея використовувати директиву noindex у файлі robots.txt, це не офіційний стандарт і Google відкрито рекомендує не використовувати його . Google не зрозумів чітко, чому, але ми вважаємо, що ми повинні сприймати їхні рекомендації (в даному випадку) серйозно. Це має сенс, тому що:
- Важко відстежувати, які сторінки слід індексувати, якщо ви використовуєте декілька способів сигналізації, щоб не індексувати сторінки.
- Noindex директива не дурень доказ, як це не офіційний стандарт. Припустимо, що 100% не буде дотримуватися Google.
- Ми знаємо лише про Google за допомогою директиви noindex, інші пошукові системи не використовуватимуть її для сторінок noindex.
Найкращий спосіб подати сигнал пошуковим системам, що сторінки не повинні бути проіндексованими, - це використання мета-робот-тег або X-Robots-Tag . Якщо ви не можете їх використовувати, а директива noindex robots.txt є вашою останньою можливістю, ніж можете спробувати, але припустити, що вона не буде повністю працювати, тоді ви не будете розчаровані.
Приклади файлів robots.txt
У цьому розділі ми розглянемо широкий спектр прикладів файлів robots.txt.
Всі роботи можуть отримати доступ до всього
Існує кілька способів розкрити пошуковим системам доступ до всіх файлів:
User-agent: * Disallow:
Або маєте порожній файл robots.txt або взагалі не маєте robots.txt.
Всі роботи не мають доступу
User-agent: * Disallow: /
Будь ласка, зверніть увагу: один додатковий символ може зробити всю різницю.
Усі боти Google не мають доступу
Агент користувача: googlebot Disallow: /
Зауважте, що при забороні Googlebot це стосується всіх Googlebots. Це включає роботів Google, які шукають, наприклад, новини (googlebot-news) і зображення (googlebot-images).
Всі боти Google, окрім новин Googlebot, не мають доступу
Агент користувача: googlebot Disallow: / User-agent: googlebot-news Disallow:
Googlebot і Slurp не мають доступу
User-agent: Slurp User-agent: googlebot Disallow: /
Всі роботи не мають доступу до двох каталогів
User-agent: * Disallow: / admin / Disallow: / private /
Всі роботи не мають доступу до одного конкретного файлу
User-agent: * Disallow: /directory/some-pdf.pdf
Googlebot не має доступу до / admin / і Slurp не має доступу до / private /
Агент користувача: googlebot Disallow: / admin / User-agent: Slurp Disallow: / private /
Robots.txt для WordPress
Файл robots.txt, наведений нижче, спеціально оптимізований для WordPress.
- Ви не бажаєте сканувати ваш розділ адміністратора.
- Ви не хочете, щоб ваші внутрішні сторінки результатів пошуку сканувалися.
- Ви не хочете, щоб ваші сторінки тегів і авторів сканувалися.
- Ви не бажаєте сканувати вашу сторінку 404.
User-agent: * Disallow: / wp-admin / #block доступ до розділу адміністратора Disallow: /wp-login.php #block доступ до розділу адміністратора Disallow: / search / #block доступ до внутрішніх сторінок результатів пошуку Disallow: *? S = * #block доступ до внутрішніх сторінок результатів пошуку Disallow: *? p = * #block доступ до сторінок, на які не вдається permalinks Disallow: * & p = * #block доступ до сторінок, на які не вдається permalinks Disallow: * & preview = * #block access для попереднього перегляду сторінок Disallow: / tag / #block доступ до сторінок тегів Disallow: / author / #block доступ до сторінок автора Disallow: / 404-error / #block доступ до сторінки 404 Sitemap: https://www.example.com/ sitemap_index.xml
Зверніть увагу, що цей файл robots.txt буде працювати в більшості випадків, але ви завжди повинні налаштувати його і перевірити, щоб переконатися, що він застосовується до вашої конкретної ситуації.
Які обмеження файлу robots.txt?
Файл Robots.txt містить директиви
Незважаючи на те, що файл robots.txt добре поважають пошукові системи, він все одно є директивою, а не мандатом.
Сторінки все ще відображаються в результатах пошуку
Сторінки, які недоступні для пошукових систем через файли robots.txt, але мають посилання на них, можуть відображатися в результатах пошуку, якщо вони пов'язані зі сканованою сторінкою. Приклад того, як це виглядає:

Protip: можна видалити ці URL-адреси з Google за допомогою інструмента видалення URL-адреси консолі пошуку Google. Зауважте, що ці URL-адреси буде тимчасово видалено. Для того, щоб вони залишалися на сторінках результатів Google, потрібно видаляти URL-адреси кожні 90 днів.
Кешування
Google вказав, що файл robots.txt, як правило, зберігається до 24 годин. Важливо враховувати це при внесенні змін у файл robots.txt.
Незрозуміло, як інші пошукові системи мають справу з кешуванням файлів robots.txt, але в цілому краще уникати кешування вашого файлу robots.txt, щоб уникнути більше часу, ніж потрібно, щоб пошукові системи могли отримувати зміни.
Розмір файлу
Для файлів robots.txt Google наразі підтримує обмеження розміру файлу 500 кб. Будь-який вміст після цього максимального розміру файлу може ігноруватися.
Незрозуміло, чи мають інші пошукові системи максимальний розмір файлів для файлів robots.txt.
Часті запитання про файл robots.txt
- Чи не використовуватиметься файл robots.txt, щоб пошукові системи не показували заборонені сторінки на сторінках результатів пошуку?
- Чи слід обережно використовувати файл robots.txt?
- Чи заборонено ігнорувати файл robots.txt під час вибору веб-сайту?
- У мене немає файлу robots.txt. Чи будуть пошукові системи ще сканувати мій веб-сайт?
- Чи можна використовувати файл Noindex замість Disallow у файлі robots.txt?
- Які пошукові системи поважають файл robots.txt?
- Як запобігти індексації пошуковими системами сторінок результатів пошуку на веб-сайті WordPress?
1. Чи запобігає використання файлу robots.txt, щоб пошукові системи не показували заборонені сторінки на сторінках результатів пошуку?
Ні, візьміть цей приклад:
Також: якщо сторінка заборонена за допомогою robots.txt, а сама сторінка містить <meta name = "robots" content = "noindex, nofollow">, то роботи пошукових систем все одно зберігатимуть сторінку в індексі, тому що вони ніколи не будуть дізнайтеся про <meta name = "robots" content = "noindex, nofollow">, оскільки вони не мають доступу.
2. Чи слід обережно використовувати файл robots.txt?
Так, ви повинні бути обережні. Але не бійтеся використовувати його. Це відмінний інструмент, який допомагає пошуковим системам краще сканувати ваш сайт.
3. Чи є незаконним ігнорувати файл robots.txt під час вибору веб-сайту?
З технічної точки зору немає. Файл robots.txt є необов'язковою директивою. Ми не можемо сказати нічого з юридичної точки зору.
4. У мене немає файлу robots.txt. Чи будуть пошукові системи ще сканувати мій веб-сайт?
Так. Коли пошукова система не зіткнеться з файлом robots.txt у корені (у каталозі верхнього рівня хоста), вони вважатимуть, що для них немає директив, і вони намагатимуться сканувати весь ваш веб-сайт.
5. Чи можу я використовувати файл Noindex замість Disallow у файлі robots.txt?
Ні, це не рекомендується. Google спеціально рекомендує проти використання директиви noindex у файлі robots.txt.
6. Які пошукові системи поважають файл robots.txt?
Ми знаємо, що всі основні пошукові системи нижче стосуються файлу robots.txt:
7. Як запобігти індексації пошуковими системами сторінок результатів пошуку на моєму веб-сайті WordPress?
Включення наступних директив у ваш файл robots.txt запобігає всім пошуковим системам індексування сторінки результатів пошуку на вашому веб-сайті WordPress, якщо не було внесено жодних змін у роботу сторінок результатів пошуку.
Агент користувача: * Disallow: /? S = Disallow: / search /
Подальше читання
Txt?Txt працює проти вас?
Txt?
Txt?
Txt?
Txt?
Txt під час вибору веб-сайту?
Чи будуть пошукові системи ще сканувати мій веб-сайт?
Txt?
Txt?