
- Як скласти семантичне ядро сайту правильно
- Оператори Яндекс. Вордстат - визначення статистики при аналізі семантичного ядра
- Підбір семантичного ядра парсером Яндекс. вордстат
- Прогноз трафіку по SEO запитам
- Що робити з запитами семантичного ядра
Семантичне ядро - це список всіх запитів пошукових систем, на які може дати відповідь ваш сайт. Відповідно, саме по цих запитах відвідувачі приходять на ваш сайт. У цьому керівництві ми докладно розглянемо приклад правильного підбору семантичного ядра для SEO просування інтернет-магазину або будь-якого сайту. За основу ми візьмемо сервіс Wordstat.yandex.ru і скористаємося інструментом для автоматичного збору запитів. Абсолютно аналогічні результати можна отримати і за допомогою сервісу від Google, але простіше і зручніше це зробити за допомогою Яндекс.Вордстата.
Дивіться відео зі створення семантичного ядра для сайту
Як скласти семантичне ядро сайту правильно
Перед початком роботи необхідно зайти в свій обліковий запис в Яндексі на сайті Wordstat.yandex.ru і визначитися з регіоном, для якого планується збір статистики для запитів. Це дуже важливо: саме статистика визначить, які слова варто включити в майбутнє семантичне ядро сайту, а від яких варто відмовитися. Наприклад, якщо ваш створений інтернет-магазин працює на Москву і МО, то саме їх і варто вибрати зі списку:
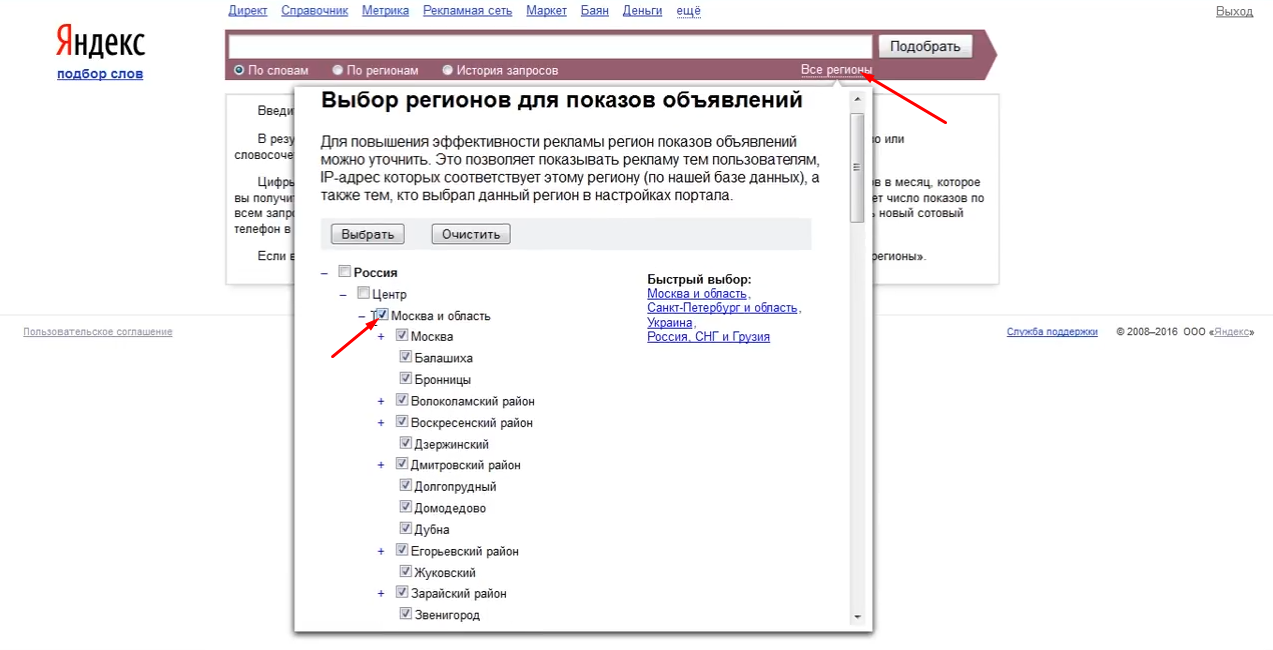
Далі приступимо до безпосередньої роботи з ключовими словами. Припустимо, що ваш інтернет-магазин продає жіночі сукні. Саме цей запит і введемо в пошукове поле і натиснемо на кнопку "Підібрати". У вікні, побачимо перші значення. Наприклад, що наш запит «Жіночі сукні» і всі пов'язані разом з ним запити по Москві і МО за місяць шукали близько 20 тисяч разів:
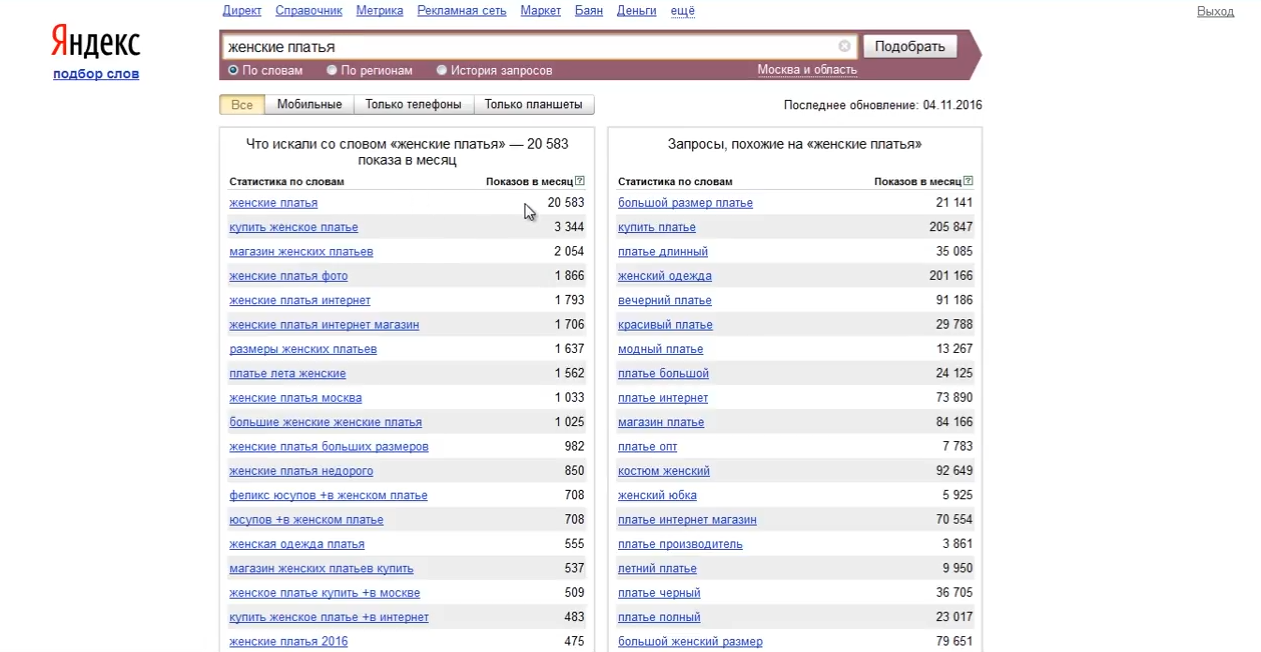
Це означає, що саме стільки разів користувачі мережі Яндекс ввели фрази, що включають в себе словосполучення «Жіночі сукні» без урахування форми і закінчень слів. Якщо подивитися трохи нижче - ви побачите інші ключові слова, які також включають в себе наш основний запит. Саме загальна сума всіх цих запитів з основних ключових словом і показана в самій першому рядку.
Оператори Яндекс. Вордстат - визначення статистики при аналізі семантичного ядра
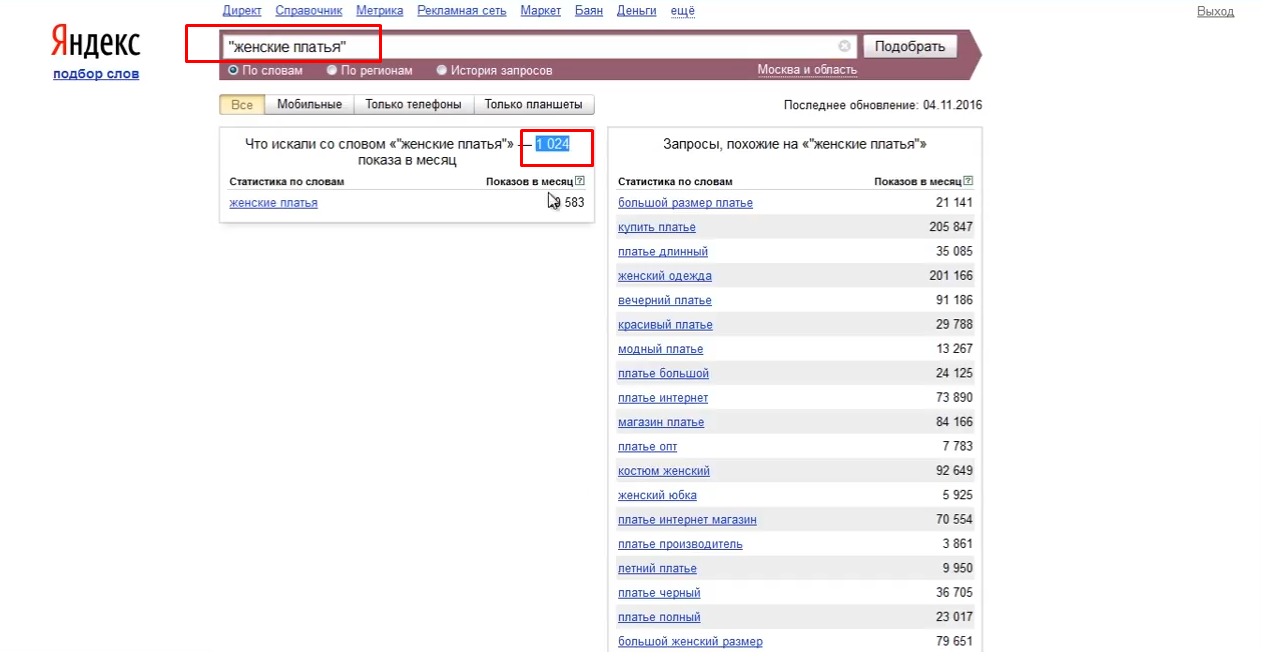
Якщо вам потрібно дізнатися, яка кількість раз шукали саме фразу «Жіночі сукні», то в поле необхідно позначить її в лапки і також натиснути на кнопку "Підібрати". В даному випадку ми отримаємо, що чисту основну фразу шукали лише близько 1 тисячі разів в середньому за місяць. Виходить, що всі інші 19 тисяч раз користувачі пошукової мережі шукали фразу «Жіночі сукні» і додавали до неї додаткові запити. Наприклад, «Жіночі сукні купити».
Перевіримо і цю фразу за точну кількість запитів щомісяця. Як показано на зображенні нижче, ключовий запит «Жіночі сукні купити» користувачі шукали всього 304 рази за місяць.
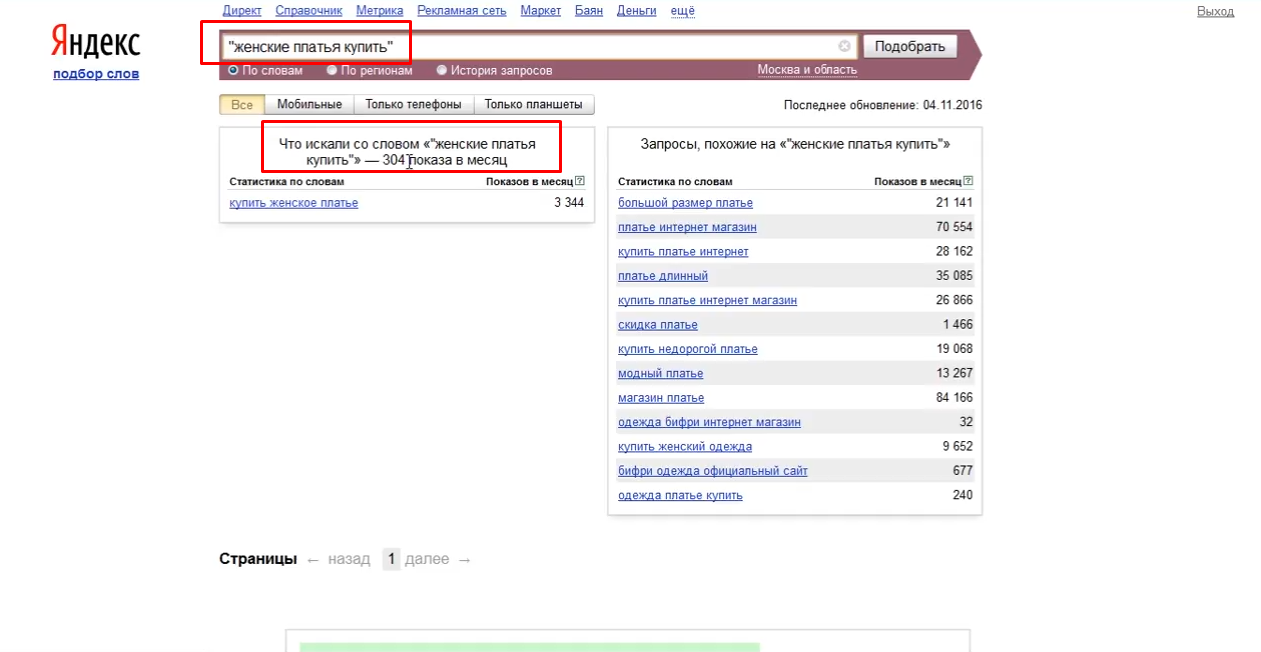
Такий спосіб дозволяє побачити реальну цінність певних запитів і не звертати уваги на загальну картину по показам.
Є також метод, що дозволяє отримати результати по точної формі пошукового запиту. Наприклад, фрази «Жіноче плаття» і «Жіночі сукні» відвідувачі пошукової мережі Яндекс шукали різну кількість разів. Для того, щоб побачити ці показники, необхідно додати знаки оклику перед словом без пробілів. Спробуємо це зробити і подивимося на отриманий результат:
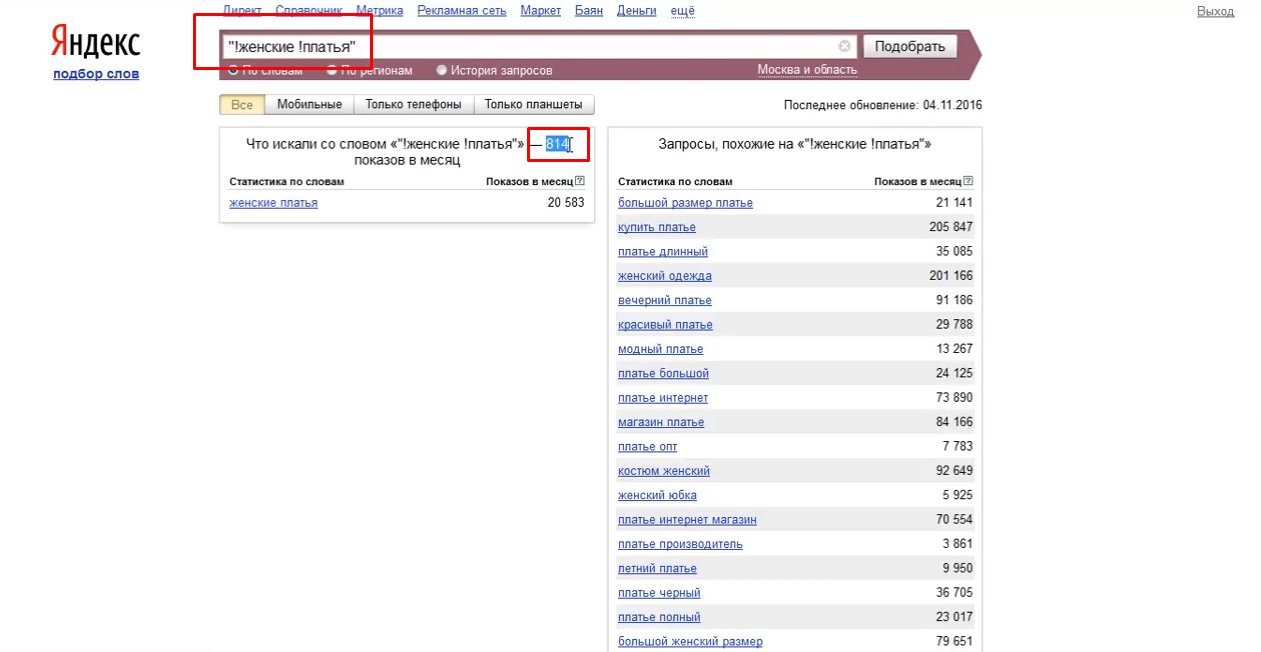
В даному випадку ми побачимо, що саме форму запиту «Жіночі сукні» по Москві і МО в середньому за місяць шукають 814 раз.
Ці методи дозволяють побачити справжню картину і зібрати саме те семантичне ядро, яке надалі принесе вам результати у вигляді трафіку і конверсій при СЕО оптимізації .
Перед початком роботи необхідно визначити основну тематику інтернет-магазину або розбити його на тематичні розділи, а вже потім шукати все розширені запити в сервісі Wordstat. Далі копіюємо всі отримані запити (з усіх сторінок) і складаємо таблицю. Далі працюємо з правого колонкою схожих за змістом і за логікою запитів. Вона допоможе доповнити майбутнє семантичне ядро і знайти цінні ключові фрази для майбутнього поступу.
Таким чином, ви отримаєте так звані «маски запитів». В даному випадку це будуть: «вечірні сукні», «жіночі сукні» і так далі. Якщо у вас інтернет-магазин загальної спрямованості, наприклад, жіночого одягу, то кількість пошукових фраз буде обчислюватися десятками тисяч і більше. Зрозуміло, що в ручну таку роботу виконати складно і проблематично. Тому, для цієї мети ми будемо використовувати окремий сервіс підбору семантичного ядра. Воно носить трохи непристойне назву, зате володіє всіма потрібними функціями і абсолютно безкоштовно на відміну від його платного аналога Key Collector.
Підбір семантичного ядра парсером Яндекс. вордстат
Відкриваємо скачані додаток СловоЁБ і натискаємо на кнопку «Створити новий проект». Озаглавлювати його і відкриваємо. Обов'язково вказуємо потрібний регіон (регіони, країну) для збору майбутнього семантичного ядра:
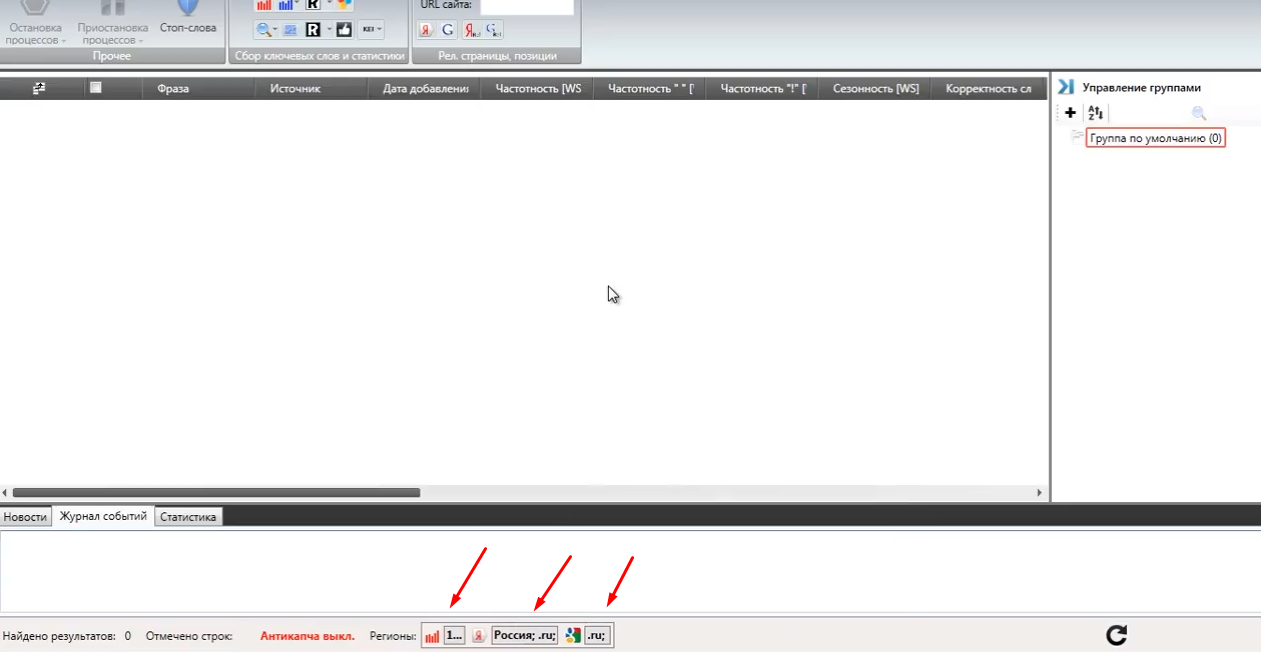
Далі введемо дані від обліковий запис на Яндексі, створеної спеціально для збору пошукових фраз. Використовуємо її тільки для даної програми. Для введення даних заходимо в налаштування у верхньому лівому кутку, вибираємо пункт в діалоговому вікні «Yandex.Direct» і вводимо в поле через двокрапку логін (без @ yandex.ru) і пароль від обліковий запис. Далі натискаємо внизу на кнопку «Зберегти зміни» і повертаємося назад в основний робочий поле програми.
Тепер перед нами стоїть велике завдання по складанню семантичного ядра по всім зібраним раніше маскам. Для початку візьмемося за список мінус-слів, які необхідно включити в роботу для чищення майбутнього семантичного ядра від непотрібних запитів.
Наприклад, за запитом маски «Жіночі сукні» ми бачимо пошукову фразу «Жіночі сукні фото». Зрозуміло, що це не конверсійний запит і для просування інтернет-магазину він нам не знадобиться.
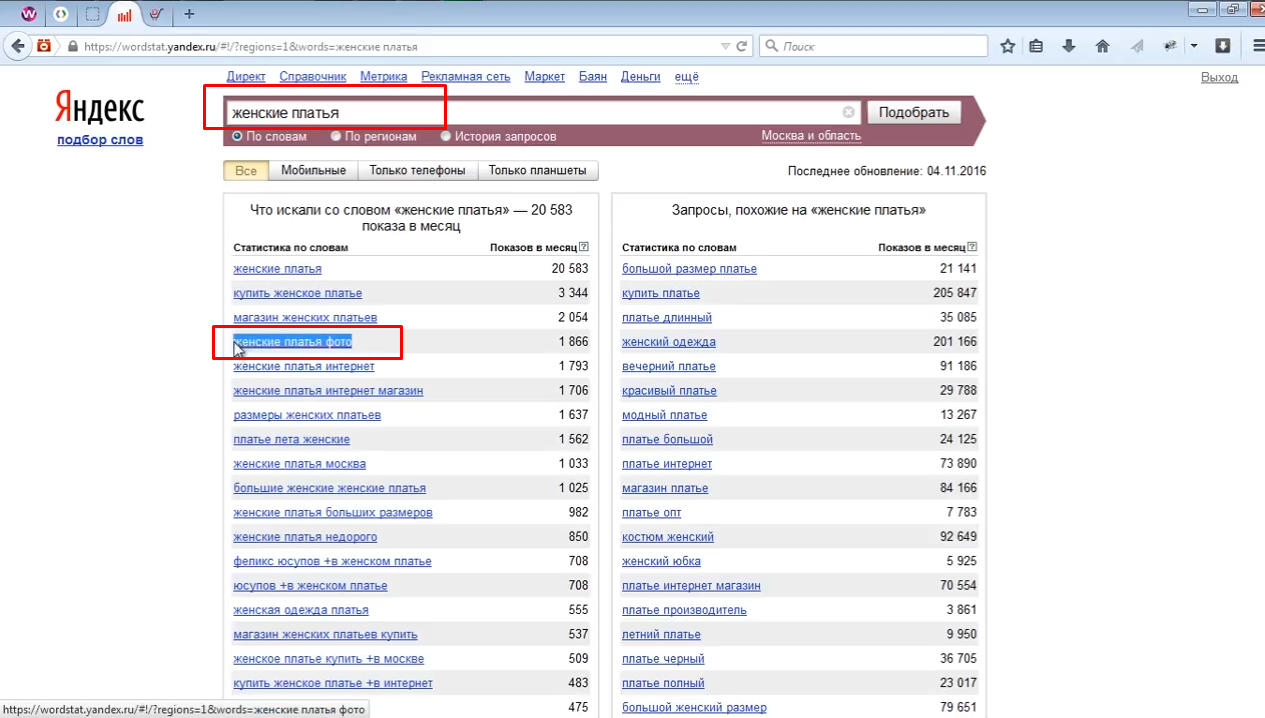
Роботу мінус-слів ви можете перевірити, ввівши їх через знак «-» після пошукової фрази (маски). В отриманих результатах фрази, що містять зазначені мінус-слова, зникнуть:
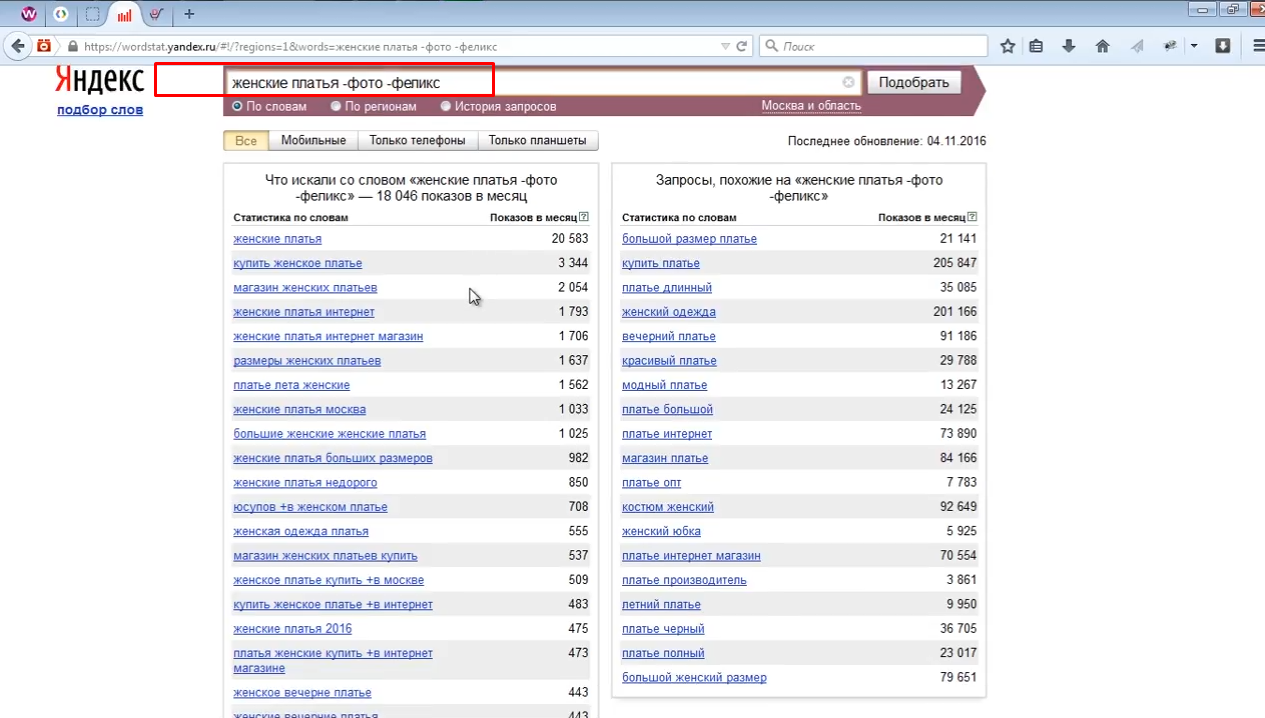
Зберемо все мінус слова з першої сторінки. Це мінімально необхідна робота. Після того, як слова будуть зібрані, необхідно занести їх в додаток. Для цього вибираємо пункт «Стоп-слова» з верхнього меню, як показано на зображенні нижче.
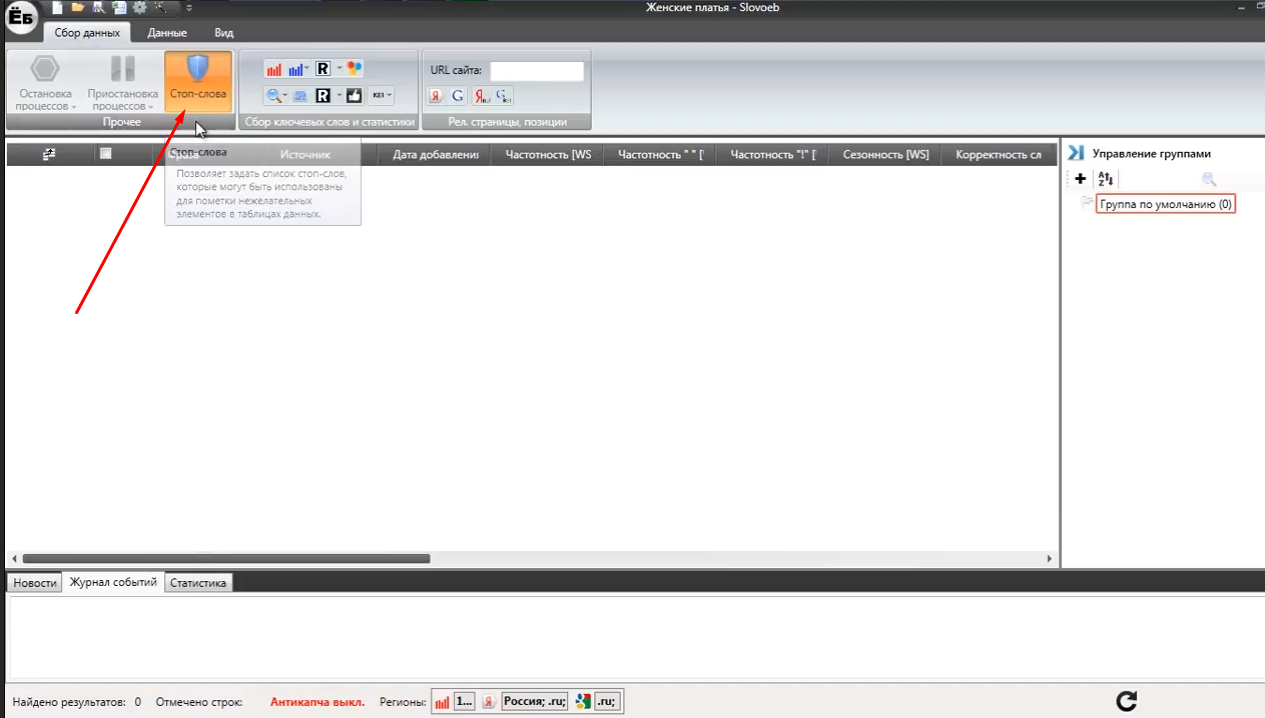
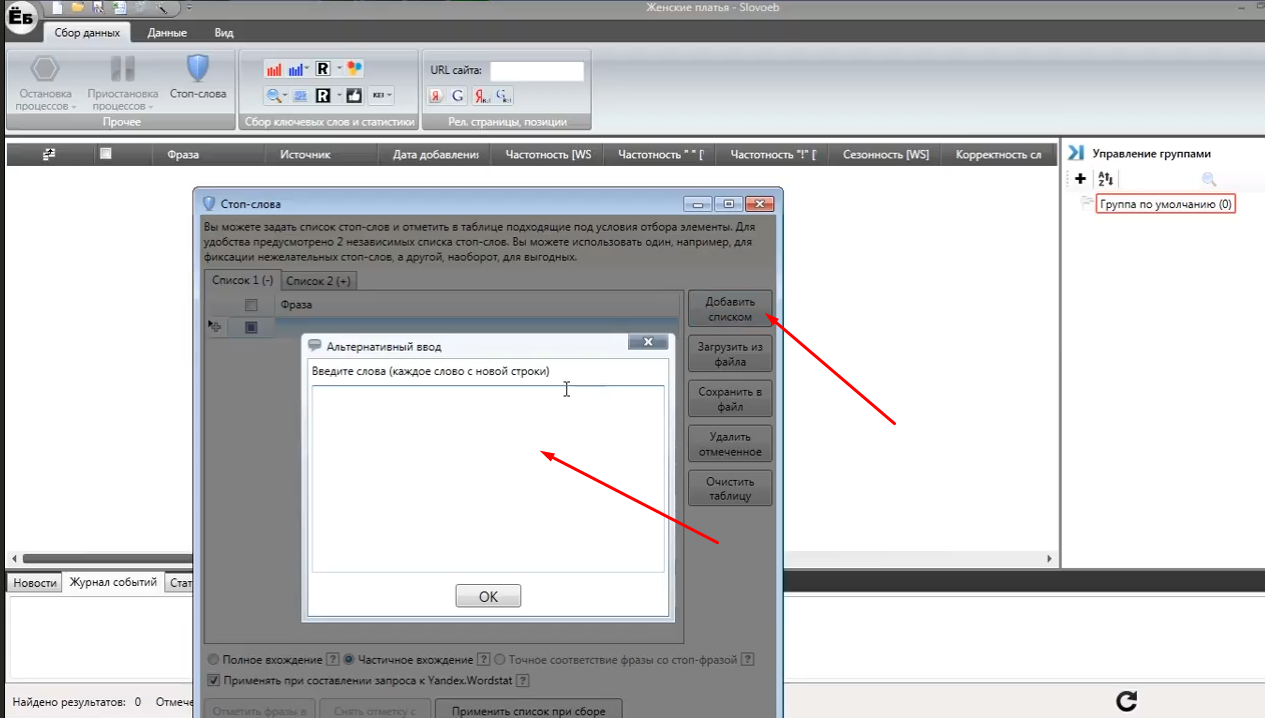
Вставимо збережені мінус-слова в відкрилося поле. Кожне слово необхідно вставити з нового рядка і без будь-яких знаків. Для чисел і для прийменників вказуємо перед фразою знак оклику. Натискаємо на кнопку «Застосувати список при зборі фраз». Готово! Тепер при подальшому підборі семантичного ядра сервіс автоматично буде видаляти ті фрази, які містять наш список з мінус-слів.
Перейдемо до роботи над зібраними масками. У правому меню нашого застосування є можливість додати групи - це і будуть маски. Додаємо, натискаючи на кнопку знака «+»:
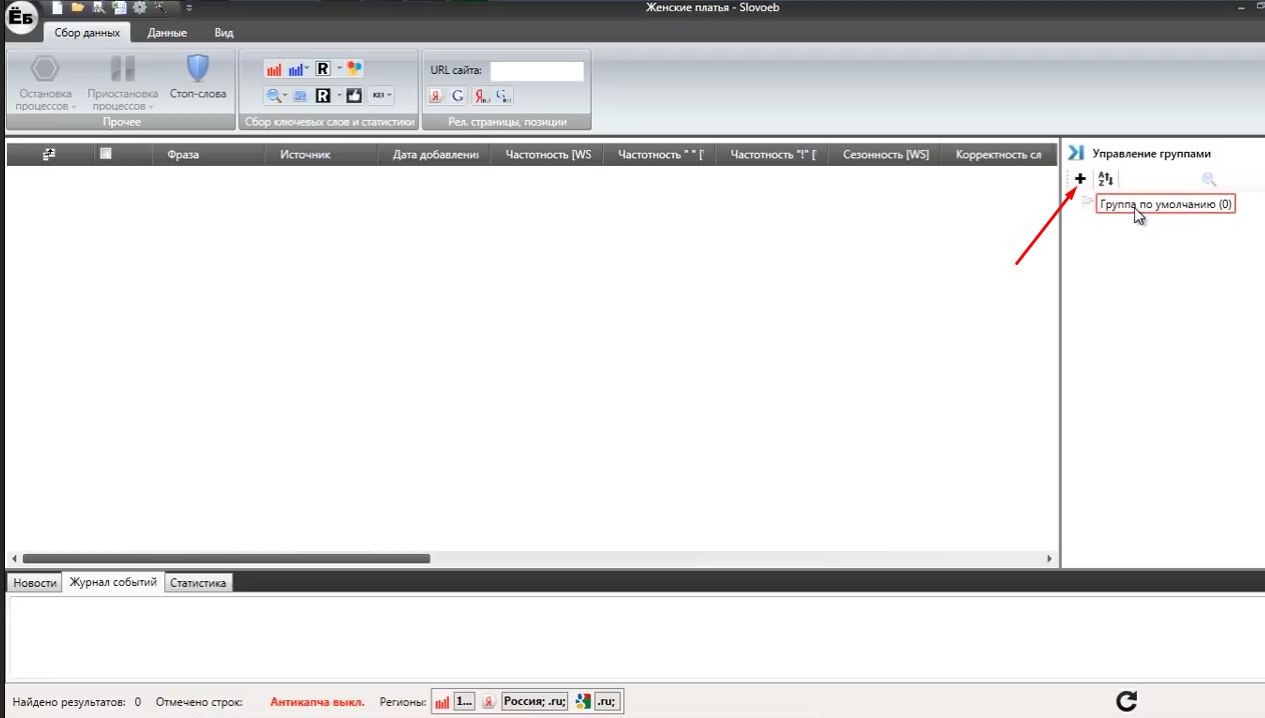
Додамо кілька для роботи. В результаті у вас повинно вийти наступне:
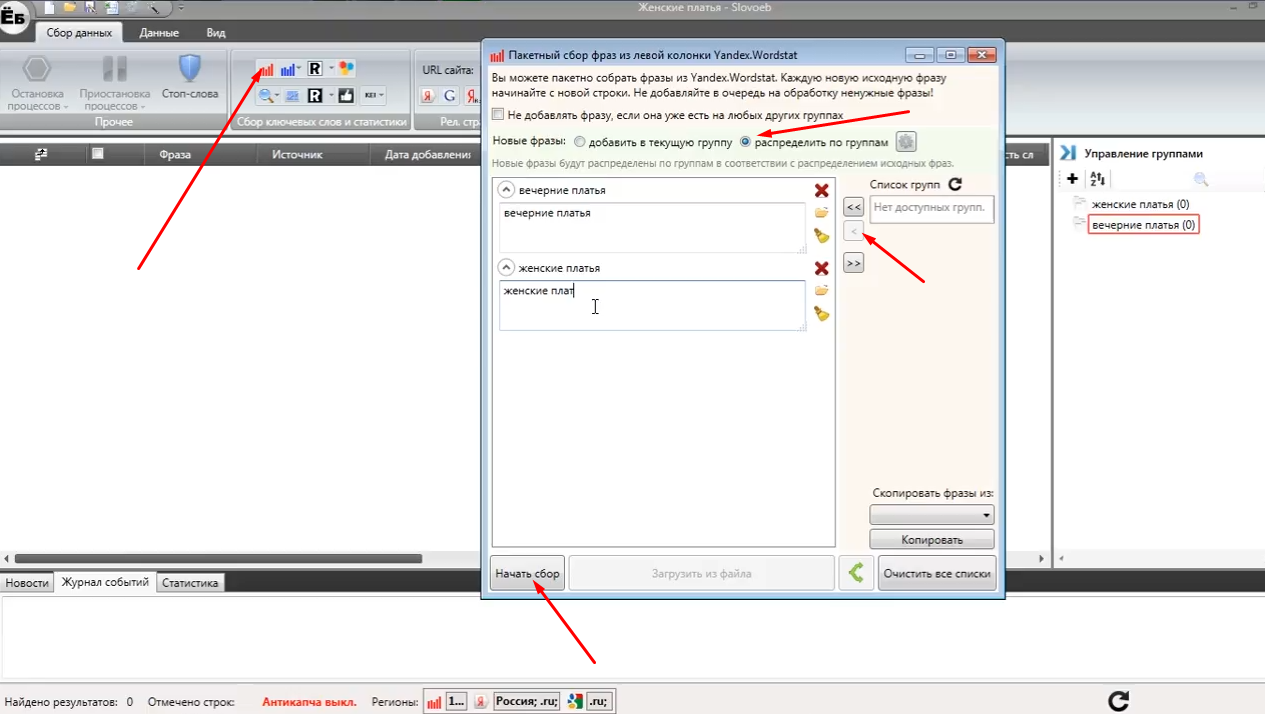
Тепер вибираємо в меню пункт «Почати пакетний збір пошукових фраз» та налаштовуємо відкрилося діалогове вікно наступним чином: вибираємо пункт «розділити по групах», додаємо за допомогою стрілок всі наші маски і дублюємо їх в кожне поле, як показано на зображенні нижче. Після закінчення всіх робіт натискаємо на кнопку «Почати збір».
Залежно від кількості масок і тематики ключових запитів збір семантичного ядра може зайняти деякий час. Мінус-слова програма автоматично видалить в процесі збору. В результаті у вас повинна вийти наступна картина:
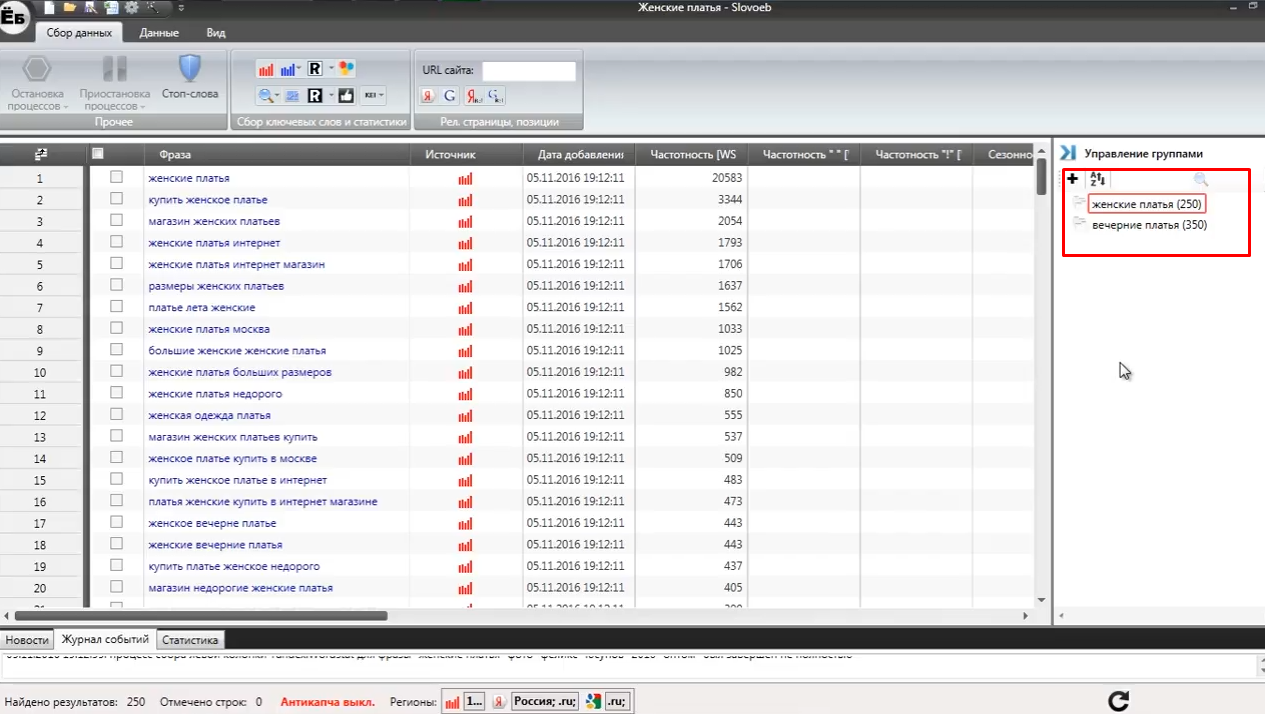
Важливо розуміти, чим є маски слів. Маски - це не пересічні запити, від яких далі відбувається збір всіх пошукових фраз. Наприклад: «вечірні сукні», «сукні весілля», «жіночі сукні» і так далі. Логічно це дуже схожі запити, але вони не перетинаються один з одним і ви зможете зібрати пул ключових фраз для кожного з них.
Далі проведемо роботу з аналізу частотності отриманих пошукових фраз. Для цього будемо використовувати частотність з лапками: таким способом ми побачимо кількість запитів саме тієї фрази, яка була знайдена додатком. Чи не фрази з різними додатками, а чистого запиту. Наприклад: скільки разів користувачі пошукової системи шукали фразу «вечірні сукні», а не пул безлічі фраз, що містять словосполучення «вечірні сукні». Завдяки такому методу перевірки ви знайдете робочі ключові фрази для SEO оптимізації , Які в подальшому варто додати до семантичному ядру.
Переходимо в наш додаток і вибираємо пункт у верхньому меню «Збір частотного для сервісу Yandex. Wordstat », далі натискаємо на« Зібрати частотності «» «.
Чекаємо, поки додаток збере частотності кожного із знайдених запитів. Цей процес може зайняти більше часу, ніж основний збір пошукових фраз. В результаті отримаємо наступну картину:
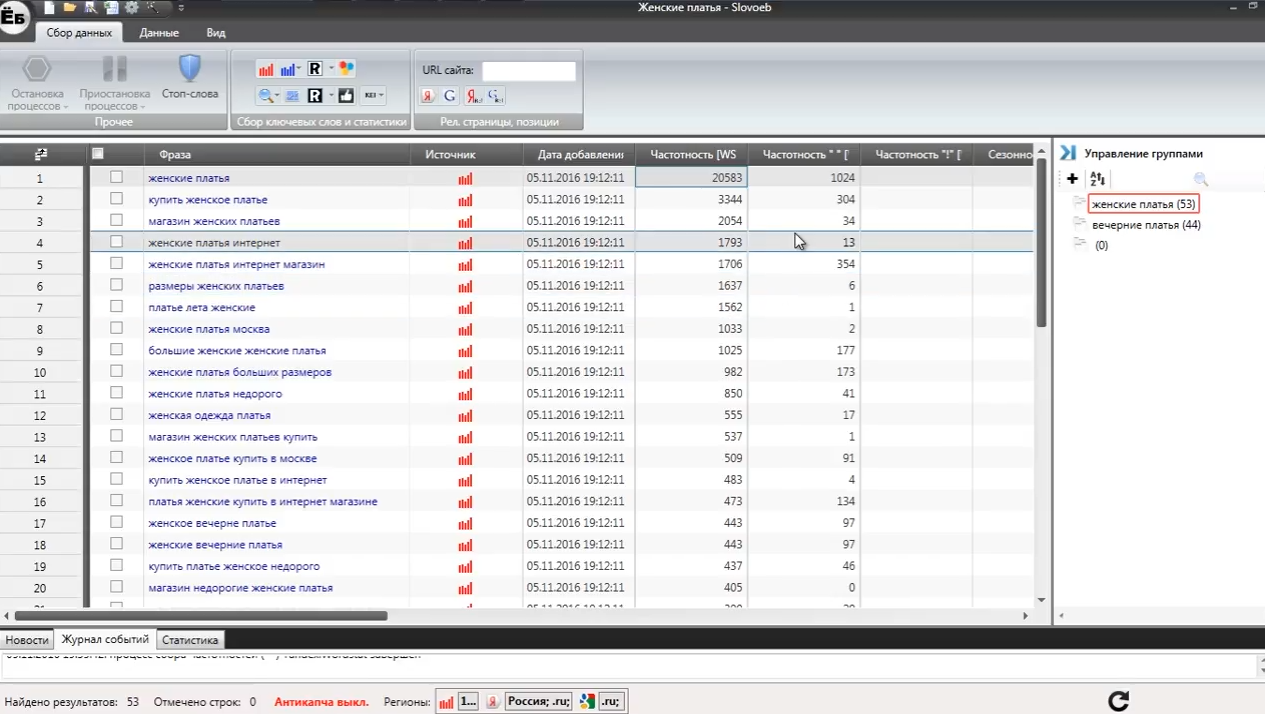
Як видно на зображенні, не завжди ті пошукові фрази, які мають велику кількість запитів за загальним збору, мають достатні показники частоти. Наприклад, «магазин жіночих суконь» шукають не близько двох тисяч чоловік, а всього 34 людини. Ця фраза не є доцільною для використання в просуванні і підлягає видаленню. Ви можете впорядкувати все частотності у напрямку зниження і видалити всі залишилися пошукові фрази, які, наприклад, мають менше 50 запитів щомісяця. Все залежить від вашої стратегії просування. І якщо вона включає в себе SEO просування по низькочастотних запитах, то варто вибирати і їх.
Експортуємо отримані результати при зборі частотного в окремі файли по групах. Це необхідно у зв'язку з тим, що семантичне ядро ми збираємо не тільки для SEO просування, але і для контекстної реклами. В останньому випадку нам не завадять запити і з частотністю менше 50 запитів в місяць по точному введенню.
Прогноз трафіку по SEO запитам
Після збереження файлів семантичного ядра, видаляємо все низькочастотні запити у всіх масках (групах). Щоб підрахувати приблизну кількість трафіку, яке ви зможете отримати в майбутньому, слід взяти 30% від отриманих показників частотності в лапках за умови потрапляння ключової фрази в той 3 безкоштовного пошуку. При попаданні на ключові слова в топ 10 можна розраховувати приблизно на 5% від показників. Ці значення сильно залежать від ніші вашого сайту і самої логічної складової запиту. при якісному СЕО просування цілком реально отримати до 70% від показників частотності фраз в лапках.
Що робити з запитами семантичного ядра
Наступний етап роботи полягає в угрупованні ключових слів . Це необхідно для того, щоб розподілити пошукові фрази по певних сторінок вашого сайту. Наприклад, для інтернет-магазину може бути окрема сторінка під запит «весільні сукні» і всі пов'язані з ними запити.
Професійною мовою подібний процес угруповання ключових слів називається « кластеризація ». Самі пошукові запити в свою чергу діляться на інформаційні та продають і потребують відповідного розподілі по сайту.
Візьмемо з нашого списку для прикладу запит «купити жіноче плаття»: він однозначно відноситься до продає типу і повинен бути включений в просування на сторінці з товарами. Такий тип трафіку здатний принести конверсії інтернет-магазину. А ось запит «жіночі сукні 30х років» відноситься до інформаційного типу і здатний принести на сайт трафік, але не прямі конверсії. Однак і такий тип пошукових фраз дуже важливий і варто того, щоб включати його в просування.
детально про кластеризацию семантичного ядра і подальшу роботу з ним ви можете дізнатися в нашому наступному уроці.