
- W skrócie Robots.txt Plik robots.txt zawiera dyrektywy dla wyszukiwarek, których można użyć, aby...
- Terminologia wokół pliku robots.txt
- Dlaczego warto troszczyć się o plik robots.txt?
- Przykład
- Czy twój robots.txt działa przeciwko tobie?
- Agent użytkownika w robots.txt
- Zabroń w robots.txt
- Przykład
- Zezwól w pliku robots.txt
- Przykład
- Przykład sprzecznych dyrektyw
- Oddzielna linia dla każdej dyrektywy
- Korzystanie ze znaku wieloznacznego *
- Przykład
- Używając końca adresu URL $
- Przykład
- Mapa witryny w robots.txt
- Przykłady
- Przykład 1
- Przykład 2
- Opóźnienie indeksowania w robots.txt
- Przykład:
- Kiedy używać pliku robots.txt?
- Najlepsze praktyki dotyczące pliku robots.txt
- Kolejność pierwszeństwa
- Przykład
- Przykład
- Tylko jedna grupa dyrektyw na robota
- Bądź jak najbardziej konkretny
- Przykład:
- Dyrektywy dla wszystkich robotów, a także dyrektywy dla konkretnego robota
- Przykład
- Plik Robots.txt dla każdej (pod) domeny
- Przykłady
- Sprzeczne wskazówki: robots.txt a Google Search Console
- Monitoruj plik robots.txt
- Skąd wiesz, kiedy zmienia się plik robots.txt?
- Nie używaj noindex w swoim robots.txt
- Przykłady pliku robots.txt
- Wszystkie roboty mają dostęp do wszystkiego
- Wszystkie roboty nie mają dostępu
- Wszystkie boty Google nie mają dostępu
- Wszystkie boty Google, z wyjątkiem wiadomości Googlebot, nie mają dostępu
- Googlebot i Slurp nie mają żadnego dostępu
- Wszystkie roboty nie mają dostępu do dwóch katalogów
- Wszystkie roboty nie mają dostępu do jednego konkretnego pliku
- Googlebot nie ma dostępu do / admin / i Slurp nie ma dostępu do / private /
- Robots.txt dla WordPress
- Jakie są ograniczenia pliku robots.txt?
- Strony nadal pojawiają się w wynikach wyszukiwania
- Buforowanie
- Rozmiar pliku
- Często zadawane pytania dotyczące robots.txt
- 1. Czy użycie pliku robots.txt uniemożliwi wyszukiwarkom wyświetlanie niedozwolonych stron na stronach wyników wyszukiwania?
- 2. Czy powinienem być ostrożny w używaniu pliku robots.txt?
- 3. Czy nielegalne jest ignorowanie robots.txt podczas zdrapywania witryny?
- 4. Nie mam pliku robots.txt. Czy wyszukiwarki nadal będą indeksować moją witrynę?
- 5. Czy mogę używać Noindex zamiast Disallow w moim pliku robots.txt?
- 6. Jakie wyszukiwarki szanują plik robots.txt?
- 7. Jak mogę uniemożliwić wyszukiwarkom indeksowanie stron wyników wyszukiwania w mojej witrynie WordPress?
W skrócie Robots.txt
Plik robots.txt zawiera dyrektywy dla wyszukiwarek, których można użyć, aby uniemożliwić wyszukiwarkom przeszukiwanie określonych części witryny.
Podczas implementacji robots.txt pamiętaj o następujących najlepszych praktykach:
- Zachowaj ostrożność podczas wprowadzania zmian w pliku robots.txt: ten plik może uniemożliwić dostęp do wyszukiwarek dużej części witryny.
- Plik robots.txt powinien znajdować się w katalogu głównym witryny (np. Http://www.example.com/robots.txt).
- Plik robots.txt jest ważny tylko dla pełnej domeny, w której się znajduje, w tym dla protokołu (http lub https).
- Różne wyszukiwarki różnie interpretują dyrektywy. Domyślnie pierwsza dopasowana dyrektywa zawsze wygrywa. Ale dzięki Google i Bingowi wygrywa specyfika.
- Unikaj korzystania z dyrektywy dotyczącej opóźnień indeksowania w wyszukiwarkach tak bardzo, jak to możliwe.
Co to jest plik robots.txt?
Plik robots.txt mówi wyszukiwarkom zasady zaangażowania Twojej witryny.
Wyszukiwarki regularnie sprawdzają plik robots.txt witryny, aby sprawdzić, czy są jakieś instrukcje dotyczące indeksowania witryny. Nazywamy te instrukcje „dyrektywami”.
Jeśli nie ma pliku robots.txt lub nie ma odpowiednich dyrektyw, wyszukiwarki będą indeksować całą witrynę.
Chociaż wszystkie główne wyszukiwarki przestrzegają pliku robots.txt, wyszukiwarki mogą zignorować (część) pliku robots.txt. Chociaż dyrektywy w pliku robots.txt są silnym sygnałem dla wyszukiwarek, ważne jest, aby pamiętać, że plik robots.txt to zestaw opcjonalnych dyrektyw dla wyszukiwarek, a nie dla mandatu.
Terminologia wokół pliku robots.txt
Plik robots.txt to implementacja standardu wykluczania robotów lub nazywany również protokołem wykluczania robotów .
Dlaczego warto troszczyć się o plik robots.txt?
Plik robots.txt odgrywa istotną rolę z punktu widzenia optymalizacji pod kątem wyszukiwarek (SEO). Informuje wyszukiwarki, w jaki sposób mogą najlepiej indeksować Twoją witrynę.
Korzystając z pliku robots.txt, możesz uniemożliwić wyszukiwarkom uzyskiwanie dostępu do określonych części witryny , zapobiegać powielaniu treści i podawać wyszukiwarkom pomocne wskazówki, w jaki sposób mogą oni wydajniej indeksować witrynę.
Zachowaj ostrożność podczas wprowadzania zmian w pliku robots.txt: ten plik może uniemożliwić dostęp do wyszukiwarek dużej części witryny.
Przykład
Spójrzmy na przykład, aby to zilustrować:
Prowadzisz witrynę handlu elektronicznego, a odwiedzający mogą skorzystać z filtra, aby szybko przeszukiwać produkty. Ten filtr generuje strony, które zasadniczo pokazują tę samą zawartość, co inne strony. To działa świetnie dla użytkowników, ale myli wyszukiwarki, ponieważ tworzy duplikat treści . Nie chcesz, aby wyszukiwarki indeksowały te filtrowane strony i marnowały swój cenny czas na te adresy URL z filtrowaną zawartością. Dlatego należy skonfigurować zasady Disallow, aby wyszukiwarki nie miały dostępu do filtrowanych stron produktów.
Zapobieganie powielaniu treści można również wykonać za pomocą kanoniczny adres URL lub tag meta robots, jednak nie dotyczą one umożliwienia wyszukiwarkom przeszukiwania tylko stron ważnych. Używanie kanonicznego adresu URL lub tagu meta robotów nie uniemożliwia wyszukiwarkom indeksowania tych stron . To uniemożliwi wyszukiwarkom wyświetlanie tych stron w wynikach wyszukiwania . Ponieważ wyszukiwarki mają ograniczyć czas indeksowania witryny , tym razem należy wydawać na strony, które chcesz wyświetlać w wyszukiwarkach.
Czy twój robots.txt działa przeciwko tobie?
Nieprawidłowo skonfigurowany plik robots.txt może hamować wydajność SEO. Sprawdź, czy tak jest w przypadku Twojej witryny od razu!
Przykład tego, jak może wyglądać prosty plik robots.txt dla witryny WordPress:
User-agent: * Disallow: / wp-admin /
Wyjaśnijmy anatomię pliku robots.txt na podstawie powyższego przykładu:
- User-agent: agent użytkownika wskazuje, dla których wyszukiwarek mają zastosowanie następujące dyrektywy.
- *: oznacza to, że dyrektywy są przeznaczone dla wszystkich wyszukiwarek.
- Disallow: jest to dyrektywa wskazująca, która treść nie jest dostępna dla agenta użytkownika.
- / wp-admin /: jest to ścieżka niedostępna dla agenta użytkownika.
Podsumowując: ten plik robots.txt mówi wszystkim wyszukiwarkom, aby trzymały się z dala od katalogu / wp-admin /.
Agent użytkownika w robots.txt
Każda wyszukiwarka powinna identyfikować się z agentem użytkownika. Roboty Google identyfikują się na przykład jako Googlebot, roboty Yahoo jako Slurp i robot Binga jako BingBot i tak dalej.
Rekord agenta użytkownika definiuje początek grupy dyrektyw. Wszystkie dyrektywy między pierwszym agentem użytkownika a następnym rekordem agenta użytkownika są traktowane jako dyrektywy dla pierwszego agenta użytkownika.
Dyrektywy mogą mieć zastosowanie do określonych agentów użytkownika, ale mogą także dotyczyć wszystkich agentów użytkownika. W takim przypadku używany jest symbol wieloznaczny: User-agent: *.
Zabroń w robots.txt
Możesz powiedzieć wyszukiwarkom, aby nie uzyskiwały dostępu do niektórych plików, stron lub sekcji witryny. Odbywa się to za pomocą dyrektywy Disallow. Po dyrektywie Disallow następuje ścieżka, do której nie należy uzyskiwać dostępu. Jeśli nie zdefiniowano ścieżki, dyrektywa jest ignorowana.
Przykład
User-agent: * Disallow: / wp-admin /
W tym przykładzie wszystkie wyszukiwarki nie mają dostępu do katalogu / wp-admin /.
Zezwól w pliku robots.txt
Dyrektywa Allow służy do przeciwdziałania dyrektywie Disallow. Dyrektywa Allow jest obsługiwana przez Google i Bing. Korzystając z dyrektyw Zezwalaj i Nie zezwalaj, możesz przekazać wyszukiwarkom, że mogą uzyskać dostęp do określonego pliku lub strony w katalogu, który w innym przypadku jest niedozwolony. Po dyrektywie Zezwalaj następuje ścieżka, do której można uzyskać dostęp. Jeśli nie zdefiniowano ścieżki, dyrektywa jest ignorowana.
Przykład
User-agent: * Allow: /media/terms-and-conditions.pdf Disallow: / media /
W powyższym przykładzie wyszukiwarki nie mają dostępu do katalogu / media /, z wyjątkiem pliku /media/terms-and-conditions.pdf.
Ważne: w przypadku jednoczesnego używania dyrektyw Zezwalaj i Zabroń, nie używaj symboli wieloznacznych, ponieważ może to prowadzić do sprzecznych dyrektyw.
Przykład sprzecznych dyrektyw
User-agent: * Allow: / directory Disallow: /*.html
Wyszukiwarki nie będą wiedziały, co zrobić z adresem URL http://www.domain.com/directory.html. Nie jest dla nich jasne, czy mają dostęp.
Oddzielna linia dla każdej dyrektywy
Każda dyrektywa powinna znajdować się w osobnej linii, w przeciwnym razie wyszukiwarki mogą się mylić podczas analizowania pliku robots.txt.
Przykład nieprawidłowego pliku robots.txt
Zapobiegaj plikowi robots.txt w następujący sposób:
User-agent: * Disallow: / directory-1 / Disallow: / directory-2 / Disallow: / directory-3 /
Korzystanie ze znaku wieloznacznego *
Symbol wieloznaczny może być nie tylko używany do definiowania agenta użytkownika, ale może być również używany do dopasowywania adresów URL. Symbol wieloznaczny jest obsługiwany przez Google, Bing, Yahoo i Ask.
Przykład
User-agent: * Disallow: / *?
W powyższym przykładzie wszystkie wyszukiwarki nie mają dostępu do adresów URL zawierających znak zapytania (?).
Używając końca adresu URL $
Aby wskazać koniec adresu URL, możesz użyć znaku dolara ($) na końcu ścieżki.
Przykład
User-agent: * Disallow: /*.php$
W powyższym przykładzie wyszukiwarki nie mają dostępu do wszystkich adresów URL, które kończą się na .php. Adresy URL z parametrami, np. Https://example.com/page.php?lang=en nie byłyby zabronione, ponieważ adres URL nie kończy się po .php.
Mapa witryny w robots.txt
Mimo że plik robots.txt został wynaleziony, aby poinformować wyszukiwarki, jakich stron nie należy indeksować , plik robots.txt może być również używany do wskazywania wyszukiwarek w mapie witryny XML. Jest to obsługiwane przez Google, Bing, Yahoo i Ask.
Mapa witryny XML powinna być określana jako bezwzględny adres URL. Adres URL nie musi znajdować się na tym samym hoście, co plik robots.txt. Odwoływanie się do mapy witryny XML w pliku robots.txt jest jedną z najlepszych praktyk, które zawsze zalecamy, mimo że mapa witryny XML została już przesłana w Konsoli wyszukiwania Google lub w Narzędziach dla webmasterów Bing. Pamiętaj, że istnieje więcej wyszukiwarek.
Pamiętaj, że możliwe jest odwołanie się do wielu map witryn XML w pliku robots.txt.
Przykłady
Wiele map witryn XML:
User-agent: * Disallow: / wp-admin / Sitemap: https://www.example.com/sitemap1.xml Mapa witryny: https://www.example.com/sitemap2.xml
Powyższy przykład mówi wszystkim wyszukiwarkom, aby nie uzyskiwały dostępu do katalogu / wp-admin / i że istnieją dwie mapy witryn XML, które można znaleźć pod adresem https://www.example.com/sitemap1.xml i https: //www.example .com / sitemap2.xml.
Pojedyncza mapa witryny XML:
User-agent: * Disallow: / wp-admin / Sitemap: https://www.example.com/sitemap_index.xml
Powyższy przykład mówi wszystkim wyszukiwarkom, aby nie miały dostępu do katalogu / wp-admin / i że mapa witryny XML znajduje się na stronie https://www.example.com/sitemap_index.xml.
Komentarze są poprzedzone znakiem # i mogą być umieszczone na początku linii lub po dyrektywie w tej samej linii. Wszystko po # zostanie zignorowane. Te komentarze są przeznaczone tylko dla ludzi.
Przykład 1
# Nie zezwalaj na dostęp do katalogu / wp-admin / dla wszystkich robotów. User-agent: * Disallow: / wp-admin /
Przykład 2
User-agent: * # Dotyczy wszystkich robotów Disallow: / wp-admin / # Nie zezwalaj na dostęp do katalogu / wp-admin /.
Powyższe przykłady komunikują się tak samo.
Opóźnienie indeksowania w robots.txt
Dyrektywa Crawl-delay jest nieoficjalną dyrektywą służącą do zapobiegania przeciążaniu serwerów zbyt dużą liczbą żądań. Jeśli wyszukiwarki mogą przeciążać serwer, dodanie opóźnienia indeksowania do pliku robots.txt jest tylko tymczasową poprawką. Faktem jest, że Twoja strona działa na złym środowisku hostingowym i powinieneś to naprawić jak najszybciej.
Sposób, w jaki wyszukiwarki radzą sobie z opóźnieniem indeksowania, jest inny. Poniżej wyjaśniamy, jak radzą sobie główne wyszukiwarki.
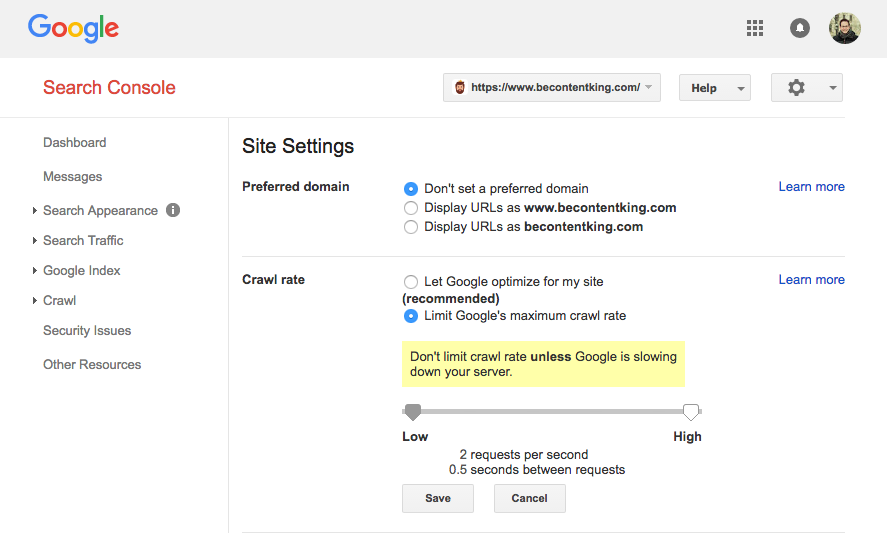
Google nie obsługuje dyrektywy opóźnienia indeksowania. Jednak Google obsługuje definiowanie szybkości indeksowania w Konsoli wyszukiwania Google. Wykonaj poniższe czynności, aby go ustawić:
- Zaloguj się do Google Search Console.
- Wybierz witrynę, dla której chcesz zdefiniować szybkość indeksowania.
- Kliknij ikonę koła zębatego w prawym górnym rogu i wybierz „Ustawienia witryny”.
- Opcja „Szybkość indeksowania” zawiera suwak, na którym można ustawić preferowaną szybkość indeksowania. Domyślnie szybkość indeksowania jest ustawiona na „Pozwól Google optymalizować dla mojej witryny (zalecane)”.
Bing, Yahoo i Yandex
Bing, Yahoo i Yandex wspierają dyrektywę Crawl-delay w celu ograniczenia indeksowania strony internetowej. Ich interpretacja opóźnienia indeksowania jest jednak inna, więc należy sprawdzić ich dokumentację:
Dyrektywa opóźnienia indeksowania powinna być umieszczona zaraz po dyrektywach Disallow lub Allow.
Przykład:
User-agent: BingBot Disallow: / private / Crawl-delay: 10
Baidu
Baidu nie obsługuje dyrektywy opóźnień indeksowania, jednak możliwe jest zarejestrowanie konta Narzędzi dla webmasterów Baidu, na którym można kontrolować częstotliwość indeksowania podobną do Google Search Console.
Kiedy używać pliku robots.txt?
Zalecamy zawsze używać pliku robots.txt. Nie ma absolutnie nic złego w posiadaniu go, a to świetne miejsce do ręcznego wyszukiwania wyszukiwarek na temat tego, jak najlepiej indeksować twoją stronę.
Najlepsze praktyki dotyczące pliku robots.txt
Najlepsze praktyki dotyczące plików robots.txt dzielą się na następujące kategorie:
Plik robots.txt należy zawsze umieszczać w katalogu głównym witryny (w katalogu najwyższego poziomu hosta) i nosić nazwę pliku robots.txt, na przykład: https://www.example.com/robots.txt . Pamiętaj, że adres URL pliku robots.txt jest, podobnie jak każdy inny adres URL, wrażliwy na wielkość liter.
Jeśli pliku robots.txt nie można znaleźć w domyślnej lokalizacji, wyszukiwarki uznają, że w witrynie nie ma żadnych dyrektyw i indeksuje się.
Kolejność pierwszeństwa
Ważne jest, aby pamiętać, że wyszukiwarki obsługują pliki robots.txt inaczej. Domyślnie pierwsza dopasowana dyrektywa zawsze wygrywa .
Jednak dzięki Google i Bing wygrywa . Na przykład: dyrektywa Zezwalaj wygrywa z dyrektywą Disallow, jeśli jej długość jest dłuższa.
Przykład
User-agent: * Zezwól: / about / company / Disallow: / about /
W powyższym przykładzie wyszukiwarki, w tym Google i Bing, nie mają dostępu do katalogu / about /, z wyjątkiem podkatalogu / about / company /.
Przykład
User-agent: * Disallow: / about / Allow: / about / company /
W powyższym przykładzie wyszukiwarki z wyjątkiem Google i Bing nie mają dostępu do katalogu / about /, w tym / about / company /.
Google i Bing mają dostęp, ponieważ dyrektywa Allow jest dłuższa niż dyrektywa Disallow.
Tylko jedna grupa dyrektyw na robota
Można zdefiniować tylko jedną grupę dyrektyw na wyszukiwarkę. Mieć wiele grup dyrektyw dla jednej wyszukiwarki myli je.
Bądź jak najbardziej konkretny
Dyrektywa disallow uruchamia się również w częściowych dopasowaniach. Przy określaniu dyrektywy Disallow, aby zapobiec niezamierzonemu uniemożliwieniu dostępu do plików, bądź jak najbardziej szczegółowy.
Przykład:
User-agent: * Disallow: / katalog
Powyższy przykład nie zezwala wyszukiwarkom na dostęp do:
- /informator
- /informator/
- / nazwa-katalogu-1
- /directory-name.html
- /directory-name.php
- / nazwa-katalogu.pdf
Dyrektywy dla wszystkich robotów, a także dyrektywy dla konkretnego robota
Dla robota ważna jest tylko jedna grupa dyrektyw. W przypadku, gdy dyrektywy dla wszystkich robotów są zgodne z dyrektywami dla konkretnego robota, tylko te szczegółowe dyrektywy zostaną wzięte pod uwagę. Aby konkretny robot mógł również przestrzegać dyrektyw dla wszystkich robotów, należy powtórzyć te dyrektywy dla konkretnego robota.
Spójrzmy na przykład, który to wyjaśni:
Przykład
User-agent: * Disallow: / secret / Disallow: / test / Disallow: / not-launch-yet / User-agent: googlebot Disallow: / not-launch-yet /
W powyższym przykładzie wyszukiwarki z wyjątkiem Google nie mają dostępu / tajne /, / test / i / nie-uruchomione-jeszcze /. Google nie ma dostępu tylko do / jeszcze nie uruchomionych /, ale ma dostęp do / tajne / i / test /.
Jeśli nie chcesz, aby googlebot miał dostęp / tajny / i / nie-uruchomiony-jeszcze / wtedy musisz powtórzyć te dyrektywy specjalnie dla googlebot:
User-agent: * Disallow: / secret / Disallow: / test / Disallow: / not-launch-yet / User-agent: googlebot Disallow: / secret / Disallow: / not-started-yet /
Pamiętaj, że plik robots.txt jest publicznie dostępny. Nie zezwalanie na sekcje stron internetowych może być wykorzystane jako wektor ataku przez osoby o złych zamiarach.
Plik Robots.txt dla każdej (pod) domeny
Dyrektywy Robots.txt dotyczą tylko domeny (pod) domeny, na której znajduje się plik.
Przykłady
http://example.com/robots.txt obowiązuje dla http://example.com, ale nie dla http: // www .example.com lub http s : //example.com.
Najlepiej jest mieć tylko jeden plik robots.txt dostępny w Twojej (pod) domenie. To koniec w ContentKing. Jeśli masz wiele plików robots.txt, upewnij się, że zwracają one status HTTP 404 lub 301-przekierowują je do kanonicznego pliku robots.txt.
Sprzeczne wskazówki: robots.txt a Google Search Console
W przypadku, gdy plik robots.txt koliduje z ustawieniami zdefiniowanymi w Google Search Console, Google często wybiera ustawienia zdefiniowane w Google Search Console w stosunku do dyrektyw zdefiniowanych w pliku robots.txt.
Monitoruj plik robots.txt
Ważne jest, aby monitorować plik robots.txt pod kątem zmian. W ContentKing widzimy wiele problemów, w których nieprawidłowe dyrektywy i nagłe zmiany w pliku robots.txt powodują poważne problemy z SEO. Dotyczy to zwłaszcza uruchamiania nowych funkcji lub nowej strony internetowej przygotowanej w środowisku testowym, ponieważ często zawierają one następujący plik robots.txt:
User-agent: * Disallow: /
Zbudowalismy śledzenie zmian i alarmowanie robots.txt z tego powodu.
Skąd wiesz, kiedy zmienia się plik robots.txt?
Widzimy to cały czas: pliki robots.txt zmieniają się bez wiedzy zespołu marketingu cyfrowego. Nie bądź tą osobą. Zacznij monitorować plik robots.txt, teraz otrzymasz powiadomienia, gdy się zmieni!
Nie używaj noindex w swoim robots.txt
Chociaż niektórzy twierdzą, że dobrym pomysłem jest użycie dyrektywy noindex w pliku robots.txt, nie jest to oficjalny standard i Google otwarcie zaleca, aby go nie używać . Google nie wyjaśniło dokładnie, dlaczego, ale uważamy, że powinniśmy poważnie potraktować ich zalecenia (w tym przypadku). To ma sens, ponieważ:
- Trudno jest śledzić, które strony nie powinny być indeksowane, jeśli używasz wielu sposobów sygnalizowania braku indeksowania stron.
- Dyrektywa noindex nie jest dowodem na to, że nie jest oficjalnym standardem. Załóżmy, że nie będzie w 100% śledzony przez Google.
- Wiemy tylko o Google za pomocą dyrektywy noindex, inne wyszukiwarki nie będą go używać na stronach noindex.
Najlepszym sposobem sygnalizowania wyszukiwarkom, że strony nie powinny być indeksowane, jest użycie meta robots tag lub X-Robots-Tag . Jeśli nie możesz ich użyć, a dyrektywa robind.txt noindex jest twoją ostatnią deską ratunku, niż możesz ją wypróbować, ale załóż, że nie będzie w pełni działać, nie będziesz rozczarowany.
Przykłady pliku robots.txt
W tym rozdziale omówimy szeroki zakres przykładów plików robots.txt.
Wszystkie roboty mają dostęp do wszystkiego
Istnieje wiele sposobów informowania wyszukiwarek, że mogą uzyskać dostęp do wszystkich plików:
User-agent: * Disallow:
Lub posiadanie pustego pliku robots.txt lub brak pliku robots.txt.
Wszystkie roboty nie mają dostępu
User-agent: * Disallow: /
Uwaga: jedna dodatkowa postać może zrobić różnicę.
Wszystkie boty Google nie mają dostępu
User-agent: googlebot Disallow: /
Pamiętaj, że wyłączenie Googlebota dotyczy wszystkich Googlebotów. Obejmuje to roboty Google, które szukają na przykład wiadomości (googlebot-news) i obrazów (googlebot-images).
Wszystkie boty Google, z wyjątkiem wiadomości Googlebot, nie mają dostępu
User-agent: googlebot Disallow: / User-agent: googlebot-news Disallow:
Googlebot i Slurp nie mają żadnego dostępu
User-agent: Slurp User-agent: googlebot Disallow: /
Wszystkie roboty nie mają dostępu do dwóch katalogów
User-agent: * Disallow: / admin / Disallow: / private /
Wszystkie roboty nie mają dostępu do jednego konkretnego pliku
User-agent: * Disallow: /directory/some-pdf.pdf
Googlebot nie ma dostępu do / admin / i Slurp nie ma dostępu do / private /
User-agent: googlebot Disallow: / admin / User-agent: Slurp Disallow: / private /
Robots.txt dla WordPress
Poniższy plik robots.txt jest specjalnie zoptymalizowany dla WordPressa, zakładając:
- Nie chcesz, aby sekcja administracyjna była indeksowana.
- Nie chcesz indeksować stron z wewnętrznymi wynikami wyszukiwania.
- Nie chcesz indeksować tagów i stron autora.
- Nie chcesz, aby Twoja strona 404 była indeksowana.
User-agent: * Disallow: / wp-admin / #block dostęp do sekcji admin Disallow: /wp-login.php #block dostęp do sekcji admin Disallow: / search / #block dostęp do wewnętrznych stron wyników wyszukiwania Disallow: *? S = * #blokuj dostęp do wewnętrznych stron wyników wyszukiwania Disallow: *? p = * #blokuj dostęp do stron, dla których permalinks nie powiedzie się Disallow: * & p = * #blokuj dostęp do stron, dla których permalinki nie powiedzie się Disallow: * i podgląd = * #blokuj dostęp aby wyświetlić podgląd stron Disallow: / tag / #block dostęp do stron tagów Disallow: / autor / #block dostęp do stron autora Disallow: / 404-error / #block dostęp do strony 404 Mapa strony: https://www.example.com/ sitemap_index.xml
Należy pamiętać, że ten plik robots.txt będzie działał w większości przypadków, ale zawsze należy go dostosować i przetestować, aby upewnić się, że dotyczy on konkretnej sytuacji.
Jakie są ograniczenia pliku robots.txt?
Plik Robots.txt zawiera dyrektywy
Mimo że robots.txt jest dobrze szanowany przez wyszukiwarki, nadal jest to dyrektywa, a nie mandat.
Strony nadal pojawiają się w wynikach wyszukiwania
Strony, które są niedostępne dla wyszukiwarek z powodu robots.txt, ale mają linki do nich, mogą nadal pojawiać się w wynikach wyszukiwania, jeśli są połączone z przeszukiwanej strony. Przykład tego, jak to wygląda:

Protip: możliwe jest usunięcie tych adresów URL z Google za pomocą narzędzia do usuwania adresów URL Google Search Console. Pamiętaj, że te adresy URL zostaną tymczasowo usunięte. Aby nie wyświetlać stron wyników Google, należy usuwać adresy URL co 90 dni.
Buforowanie
Google wskazało, że plik robots.txt jest zazwyczaj buforowany przez maksymalnie 24 godziny. Ważne jest, aby wziąć to pod uwagę, wprowadzając zmiany w pliku robots.txt.
Nie jest jasne, w jaki sposób inne wyszukiwarki radzą sobie z buforowaniem pliku robots.txt, ale generalnie najlepiej unikać buforowania pliku robots.txt, aby uniknąć sytuacji, w której wyszukiwarki będą potrzebować więcej czasu, niż potrzeba, aby móc śledzić zmiany.
Rozmiar pliku
W przypadku plików robots.txt Google obsługuje obecnie limit rozmiaru pliku wynoszący 500 kb. Każda treść po tym maksymalnym rozmiarze pliku może zostać zignorowana.
Nie jest jasne, czy inne wyszukiwarki mają maksymalny rozmiar plików dla plików robots.txt.
Często zadawane pytania dotyczące robots.txt
- Czy użycie pliku robots.txt uniemożliwi wyszukiwarkom wyświetlanie niedozwolonych stron na stronach wyników wyszukiwania?
- Czy powinienem uważać na używanie pliku robots.txt?
- Czy ignorowanie robots.txt podczas drapania strony internetowej jest nielegalne?
- Nie mam pliku robots.txt. Czy wyszukiwarki nadal będą indeksować moją witrynę?
- Czy mogę używać Noindex zamiast Disallow w moim pliku robots.txt?
- Jakie wyszukiwarki szanują plik robots.txt?
- Jak mogę uniemożliwić wyszukiwarkom indeksowanie stron wyników wyszukiwania w mojej witrynie WordPress?
1. Czy użycie pliku robots.txt uniemożliwi wyszukiwarkom wyświetlanie niedozwolonych stron na stronach wyników wyszukiwania?
Nie, weź ten przykład:
Ponadto: jeśli strona jest zabroniona za pomocą robots.txt, a sama strona zawiera <meta name = "roboty" content = "noindex, nofollow">, roboty wyszukiwarek nadal będą przechowywać stronę w indeksie, ponieważ nigdy dowiedz się o <meta name = "robotach" content = "noindex, nofollow">, ponieważ nie mają dostępu.
2. Czy powinienem być ostrożny w używaniu pliku robots.txt?
Tak, powinieneś być ostrożny. Ale nie bój się go używać. To świetne narzędzie, które pomaga wyszukiwarkom lepiej indeksować Twoją witrynę.
3. Czy nielegalne jest ignorowanie robots.txt podczas zdrapywania witryny?
Z technicznego punktu widzenia nie. Plik robots.txt jest dyrektywą opcjonalną. Nie możemy nic powiedzieć, jeśli z prawnego punktu widzenia.
4. Nie mam pliku robots.txt. Czy wyszukiwarki nadal będą indeksować moją witrynę?
Tak. Gdy wyszukiwarka nie napotka pliku robots.txt w katalogu głównym (w katalogu najwyższego poziomu hosta), zakładają, że nie ma dla nich dyrektyw i będą próbować przeszukać całą witrynę.
5. Czy mogę używać Noindex zamiast Disallow w moim pliku robots.txt?
Nie, nie jest to zalecane. Google szczególnie odradza stosowanie dyrektywy noindex w pliku robots.txt.
6. Jakie wyszukiwarki szanują plik robots.txt?
Wiemy, że wszystkie poniższe wyszukiwarki respektują plik robots.txt:
7. Jak mogę uniemożliwić wyszukiwarkom indeksowanie stron wyników wyszukiwania w mojej witrynie WordPress?
Dołączenie następujących dyrektyw do pliku robots.txt uniemożliwia wszystkim wyszukiwarkom indeksowanie strony wyników wyszukiwania w witrynie WordPress, zakładając, że nie wprowadzono żadnych zmian w funkcjonowaniu stron wyników wyszukiwania.
User-agent: * Disallow: /? S = Disallow: / search /
Dalsza lektura
Txt?Txt działa przeciwko tobie?
Txt?
Txt?
Txt?
Txt uniemożliwi wyszukiwarkom wyświetlanie niedozwolonych stron na stronach wyników wyszukiwania?
Txt?
Txt podczas zdrapywania witryny?
Czy wyszukiwarki nadal będą indeksować moją witrynę?
Txt?